En dybdegående gennemgang af IMDB-databaser: Afsløring af dataene bag verdens største filmdatabase. Opdag, hvordan disse databaser transformerer filmanalyse og industriforskning.
- Introduktion til IMDB-databaser og deres betydning
- Oversigt over tilgængelige IMDB-databases filer
- Datastruktur og skema forklaret
- Adgang til og download af IMDB-data
- Rengøring og forbehandling af IMDB-databaser
- Analyse af filmvurderinger og trends
- Udforskning af rollebesætning, besætning og industrinetværk
- Anvendelser inden for maskinlæring og AI
- Begrænsninger, bias og overvejelser om datakvalitet
- Fremtidige retninger og nye anvendelsestilfælde
- Kilder & Referencer
Introduktion til IMDB-databaser og deres betydning
Den Internet Movie Database (IMDb) er en af verdens mest omfattende og autoritative kilder til information relateret til film, tv-programmer, videospil og streamingindhold. Etableret i 1990, er IMDb vokset til at omfatte millioner af titler og personligheder og fungerer som en kritisk ressource for branchefolk, forskere og entusiaster. IMDb-databasene er kuraterede samlinger af strukturerede data udvundet fra hoved IMDb-databasen, der er gjort tilgængelige for offentligheden under specifikke licensvilkår. Disse databaser inkluderer et bredt udvalg af information som filmtitler, detaljer om rollebesætning og besætning, udgivelsesdatoer, genrer, bedømmelser og brugeranmeldelser.
Betydningen af IMDb-databaser ligger i deres bredde, dybde og pålidelighed. Da dataene vedligeholdes og opdateres af IMDb, et datterselskab af Amazon, drager de fordel af streng datakuratering og en stor brugerbase, der bidrager til deres nøjagtighed. Forskere inden for felter som datavidenskab, maskinlæring, samfundsvidenskaber og digitale humaniora bruger IMDb-databaser til at analysere trends i medieproduktion og forbrug, studere genreudvikling og udvikle anbefalingssystemer. For eksempel bruges databaserne ofte til at træne algoritmer til at forudsige filmsucces, forstå publikumspræferencer og kortlægge karrierer for skuespillere og instruktører.
Desuden fremmer den åbne tilgængelighed af IMDb-databaser gennemsigtighed og reproducerbarhed i akademisk forskning. Ved at tilbyde standardiserede, maskinlæsbare data gør IMDb det muligt for forskere at validere fund og bygge videre på tidligere arbejde. Databaserne er også vigtige i uddannelsesmæssige sammenhænge, hvor studerende lærer at manipulere virkelige data og anvende statistiske eller beregningsmæssige teknikker. Uden for akademia udnytter branchefolk IMDb-databaser til markedsanalyse, indholdsanskaffelsesstrategier og konkurrencebenchmarking.
Sammenfattende repræsenterer IMDb-databaser en grundlæggende ressource for alle, der søger at analysere eller forstå det globale underholdningslandskab. Deres omfattende omfang, regelmæssige opdateringer og autoritative oplevelse gør dem uundgåelige for en bred vifte af analytiske, uddannelsesmæssige og kommercielle anvendelser. Som underholdningsindustrien fortsætter med at udvikle sig, vil rollen som strukturerede, tilgængelige data som de, der leveres af IMDb, kun vokse i betydning.
Oversigt over tilgængelige IMDB-databases filer
Den Internet Movie Database (IMDb) er en omfattende online ressource for information relateret til film, tv-programmer, hjemmevideoer, videospil og streamingindhold. For at støtte forskning, dataanalyse og applikationsudvikling tilbyder IMDb et udvalg af downloadable databaser, der dækker et bredt spektrum af data fra underholdningsindustrien. Disse databaser gøres tilgængelige under IMDb Datasets-initiativet, som har til formål at muliggøre ikke-kommerciel brug og akademisk forskning.
IMDb-databaserne distribueres som almindelige tekstfiler i tab-separerede værdiformater (TSV), hvilket gør dem tilgængelige for behandling med en række dataanalyseværktøjer og programmeringssprog. Hver fil fokuserer på et specifikt aspekt af databasen, hvilket giver brugerne mulighed for kun at vælge de data, der er relevante for deres behov. De vigtigste databasefiler, der aktuelt er tilgængelige, inkluderer:
- title.basics.tsv.gz: Indeholder væsentlige oplysninger om titler, såsom film, tv-serier og episoder. Nøglefelter inkluderer titeltype, primære og oprindelige titler, udgivelsesår, varighed og genre.
- title.akas.tsv.gz: Giver alternative titler til værker, herunder regionale og sprog-specifikke variationer, samt oplysninger om landet og sproget for hver titels version.
- title.principals.tsv.gz: Lister den primære rollebesætning og besætning for hver titel, herunder skuespillere, instruktører og manuskriptforfattere, sammen med deres roller og rækkefølge.
- title.crew.tsv.gz: Detaljerer instruktører og manuskriptforfattere knyttet til hver titel, ved hjælp af unikke identifikatorer for hver person.
- title.episode.tsv.gz: Indeholder episode-specifikke data for tv-serier, der forbinder episoder med deres overordnede serier og giver sæson- og episodenumre.
- title.ratings.tsv.gz: Tilbyder bruger-genererede vurderinger og antallet af stemmer for hver titel, hvilket afspejler publikumsmodtagelse.
- name.basics.tsv.gz: Indeholder oplysninger om personer i branchen, såsom fødsels- og dødsår, primære erhverv og kendte titler.
Disse databaser opdateres regelmæssigt for at afspejle de nyeste oplysninger i IMDb-databasen. Adgang til databaserne gives til personlig og ikke-kommerciel brug, og brugerne skal overholde de brugsbetingelser, der er angivet af IMDb. Databaserne anvendes i vid udstrækning i akademisk forskning, maskinlæringsprojekter og datadrevne applikationer, der kræver struktureret information om den globale underholdningsindustri.
Datastruktur og skema forklaret
IMDb-databaserne er en omfattende samling af strukturerede datafiler, der giver detaljeret information om film, tv-shows, videospil og relaterede enheder. Disse databaser gøres offentligt tilgængelige af IMDb, et datterselskab af Amazon, som er anerkendt som en af verdens største og mest autoritative kilder til film- og tv-metadata. Databaserne distribueres primært i form af tab-separerede værdifiler (TSV), hvor hver repræsenterer et specifikt aspekt af underholdningsområdet.
Hver IMDb-databasefil er organiseret som en tabel, hvor rækkerne repræsenterer individuelle poster, og kolonnerne svarer til specifikke attributter. Skemaet for hver fil er eksplicit defineret, hvilket sikrer konsistens og faciliterer automatiseret parsing. For eksempel indeholder title.basics.tsv-filen kerneoplysninger om titler, med kolonner som tconst (en unik identifikator for hver titel), titleType (f.eks. film, tvSerie), primaryTitle, originalTitle, isAdult, startYear, endYear, runtimeMinutes og genres. Denne struktur gør det muligt for brugere at filtrere og analysere titler baseret på en bred vifte af kriterier.
Andre nøglefiler inkluderer name.basics.tsv (der indeholder oplysninger om personer som skuespillere, instruktører og manuskriptforfattere), title.crew.tsv (der lister instruktører og manuskriptforfattere for hver titel), title.principals.tsv (der detaljerer den primære rollebesætning og besætning) og title.ratings.tsv (der giver brugervurderinger og stemmetællinger). Hver fil bruger en unik identifikator, f.eks. tconst for titler og nconst for navne, for at muliggøre relationelle joins på tværs af databaserne, hvilket understøtter komplekse forespørgsler og dataintegration.
Skemaet er designet til at være både menneskelæsbart og maskinevenligt, hvor manglende værdier repræsenteres ved strengen N. Denne tilgang sikrer, at databaserne nemt kan importeres til relationelle databaser, dataanalyseværktøjer eller programmeringsmiljøer til videre behandling. Den eksplicitte dokumentation af hver fils skema, herunder datatyper og feltbeskrivelser, vedligeholdes af IMDb for at støtte gennemsigtighed og reproducerbarhed i forskning og udviklingsarbejde.
Samlet set gør IMDb-databasernes strukturerede skema og klare dataorganisation dem til en værdifuld ressource for datavidenskabsfolk, forskere og udviklere, der er interesseret i at udforske trends, relationer og mønstre inden for den globale underholdningsindustri.
Adgang til og download af IMDB-data
Den Internet Movie Database (IMDb) er en af verdens mest omfattende opbevaringssteder for information relateret til film, tv-programmer, videospil og relaterede medier. For forskere, udviklere og dataentusiaster tilbyder IMDb et sæt downloadable databaser, der muliggør storstilet analyse og applikationsudvikling. Disse databaser gøres tilgængelige via IMDb officielle hjemmeside, som drives af IMDb.com, Inc., et datterselskab af Amazon.com, Inc.
Adgang til IMDb-databaser er ligetil. IMDb tilbyder en dedikeret sektion til database-downloads, kendt som IMDb Datasets-siden. Her kan brugere finde en samling af almindelige tekstfiler i tab-separerede værdiformater (TSV). Disse filer dækker et bredt spektrum af data, herunder grundlæggende titeloplysninger, vurderinger, detaljer om rollebesætning og besætning, episodevejledninger og mere. Databaserne opdateres regelmæssigt, typisk en gang om ugen, hvilket sikrer, at brugerne har adgang til de mest aktuelle oplysninger, der er tilgængelige.
For at downloade databaserne behøver brugerne ikke at registrere sig eller logge ind. Filene er frit tilgængelige til personlig og ikke-kommerciel brug, som angivet i IMDb’s licensvilkår. Hver databasfil følger en datadictionary, der beskriver felterne og deres betydninger, hvilket er essentiel for korrekt datafortolkning og integration. De mest almindeligt anvendte filer inkluderer:
- title.basics.tsv.gz: Indeholder væsentlige oplysninger om film, tv-shows og videospil, såsom titel, udgivelsesår og genre.
- title.ratings.tsv.gz: Tilbyder IMDb brugerbedømmelser og stemmetællinger for hver titel.
- name.basics.tsv.gz: Lister nøgledetaljer om personer i branchen, herunder skuespillere, instruktører og manuskriptforfattere.
- title.crew.tsv.gz: Detaljerer instruktører og manuskriptforfattere for hver titel.
- title.principals.tsv.gz: Identificerer den primære rollebesætning og besætning for hver titel.
Efter download kan de komprimerede filer udpakkes og behandles ved hjælp af standard dataanalyseværktøjer eller programmeringssprog som Python eller R. Det åbne format og klare dokumentation gør IMDb-databaserne meget tilgængelige til en række forsknings- og udviklingsformål. Brugere bør dog altid gennemgå licensvilkårene for at sikre overholdelse af IMDBs brugsretning.
For mere information og adgang til databaserne, bør brugere henvende sig direkte til den officielle IMDb hjemmeside, der forbliver den autoritative kilde for alle IMDb-data og dokumentation.
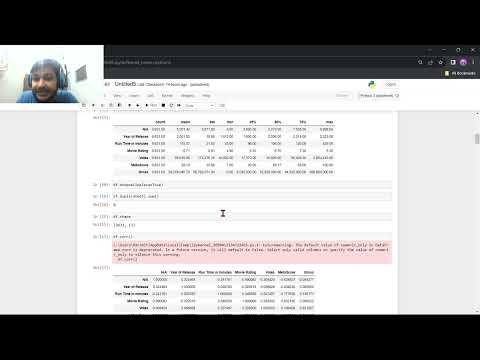
Rengøring og forbehandling af IMDB-databaser
IMDB-databaserne, der leveres af IMDb, er en omfattende ressource for film- og tv-data, der anvendes bredt i akademisk forskning, datavidenskab og maskinlæringsprojekter. Før disse databaser kan udnyttes effektivt til analyse eller modellæring, er en grundig rengørings- og forbehandlingsfase essentiel. Denne proces sikrer datakvalitet, konsistens og egnethed til efterfølgende opgaver.
IMDB-databaser distribueres typisk som tab-separerede værdifiler (TSV), hvor hver repræsenterer forskellige aspekter såsom titler, vurderinger, besætning og primær rollebesætning. Det første skridt i rengøringen involverer håndtering af manglende værdier, som ofte betragtes som strengen “N”. Disse manglende poster kan forekomme i felter som fødselsdatoer, dødsdatoer eller sekundære attributter. Afhængigt af analyseformålene kan manglende værdier imputeres, fjernes eller flagges til særlig behandling.
Et andet kritisk aspekt er konvertering af datatyper. Mange felter i IMDB-databaserne, såsom år, varighed og vurdering, læses oprindeligt som strenge. At konvertere disse til passende numeriske eller datetime-formater er nødvendigt for nøjagtig beregning og analyse. For eksempel bør felterne “startYear” og “endYear” analyseres som heltal, mens “averageRating” skal konverteres til et float-nummer.
Deduplication er også vigtigt, da databaserne kan indeholde gentagne poster som følge af opdateringer eller sammenlægninger fra forskellige datakilder. At sikre, at hver film, episode eller person er unikt repræsenteret, forhindrer skæve resultater i statistiske analyser eller maskinlæringsmodeller.
Normalisering af kategoriske data, såsom genrer eller erhverv, er et andet nøgleforbehandlingstrin. IMDB-databaserne lister ofte flere genrer eller roller i et enkelt felt, adskilt af kommaer. At opdele disse i individuelle kategorier eller bruge one-hot encoding kan lette mere granulær analyse og modelindgang.
Endelig er sammenkobling af flere IMDB-databasefiler en almindelig forbehandlingsopgave. For eksempel muliggør linkning af “title.basics”-filen (der indeholder filmmetadata) med “title.ratings” (der indeholder brugervurderinger) via den unikke “tconst”-identifikator rigere, multidimensionel analyse. Der skal tages hensyn til at sikre referentiel integritet og håndtering af tilfælde, hvor poster findes i en fil, men ikke en anden.
Ved systematisk at tackle manglende værdier, datatyper, dubletter, kategorisk normalisering og datasetintegration kan forskere og praktikere omdanne rå IMDB-data til et rent, struktureret format klar til avanceret analyse og maskinlæringsapplikationer. Den officielle IMDb hjemmeside giver detaljeret dokumentation og skemabeskrivelser for at vejlede disse forbehandlingsanstrengelser.
Analyse af filmvurderinger og trends
Den Internet Movie Database (IMDb) er en af verdens mest omfattende og autoritative kilder til information om film, tv-shows og relateret indhold. Dens databaser anvendes i vid udstrækning til at analysere filmvurderinger og trends og tilbyder en rig ressource for forskere, datavidenskabsfolk og brancheprofessionelle. IMDb-databaserne gøres offentligt tilgængelige til ikke-kommerciel brug og opdateres regelmæssigt for at afspejle de nyeste oplysninger i underholdningsindustrien.
IMDb-databaserne inkluderer en række filer, der dækker forskellige aspekter af film- og tv-data. Nøgle-databaser relevante for at analysere filmvurderinger og -trends inkluderer:
- title.basics.tsv: Indeholder væsentlige oplysninger om film og tv-shows, som titel, udgivelsesår, varighed og genre.
- title.ratings.tsv: Tilbyder gennemsnitlige brugervurderinger og antallet af stemmer for hver titel, som er afgørende for trendanalyse og forståelse af publikumspræferencer.
- title.akas.tsv: Lister alternative titler og internationale versioner, nyttige til analyse på tværs af markeder.
- name.basics.tsv: Inkluderer data om skuespillere, instruktører og andet nøglepersonale, der muliggør studier af indflydelsen fra rollebesætning og besætning på vurderinger.
Ved at udnytte disse databaser kan analytikere spore, hvordan filmvurderinger udvikler sig over tid, identificere mønstre i publikumspræferencer og korrelere vurderinger med faktorer som genre, udgivelsesår eller involvering af specifikke skuespillere og instruktører. For eksempel kan tidsserieanalyse af title.ratings.tsv-filen afsløre tendenser i publikumsfølelser, mens krydsreferencen med title.basics.tsv muliggør segmentering efter genre eller oprindelsesland.
Den åbne tilgængelighed af IMDb-databaser har også muliggjort udviklingen af maskinlæringsmodeller til at forudsige filmsucces, sentimentanalyse af brugeranmeldelser og netværksanalyse af samarbejder inden for filmindustrien. Disse databaser anvendes i vid udstrækning i akademisk forskning, brancheanalyse og af hobbyister, der er interesserede i filmdata.
IMDb ejes og drives af Amazon, som sikrer pålideligheden og regelmæssige opdateringer af dens data. Databaserne er tilgængelige gennem den officielle IMDb hjemmeside, og deres struktur og dokumentation opretholdes for at støtte en bred vifte af analytiske applikationer.
Sammenfattende giver IMDb-databaser en grundlæggende ressource til at analysere filmvurderinger og trends, som understøtter både kvantitativ og kvalitativ forskning i dynamikken i den globale underholdningsindustri.
Udforskning af rollebesætning, besætning og industrinetværk
Den Internet Movie Database (IMDb) er en omfattende online ressource for information relateret til film, tv-programmer, hjemmevideoer, videospil og streamingindhold. En af dens mest værdifulde aktiver for forskere og brancheprofessionelle er sættet af IMDb-databaser, der giver strukturerede data om rollebesætning, besætning og industrinetværk. Disse databaser gøres tilgængelige til ikke-kommerciel brug og anvendes bredt i akademisk forskning, dataanalyse og udvikling af underholdningsrelaterede applikationer.
IMDb-databaserne inkluderer flere nøglefiler, der faciliterer udforskningen af rollebesætning og besætningsrelaterede forhold. Filen name.basics.tsv lister enkeltpersoner involveret i underholdningsindustrien, herunder skuespillere, instruktører, manuskriptforfattere og andre fagfolk, sammen med deres unikke identifikatorer, fødsels- og dødsår samt primære erhverv. Filen title.principals.tsv forbinder disse individer til specifikke titler, detaljering af deres roller (såsom skuespiller, instruktør eller producent) og de karakterer, de portrætterer eller de funktioner, de udfører. Denne relationelle struktur gør det muligt for brugerne at kortlægge de professionelle netværk, der understøtter film- og tv-industrien.
Ved at udnytte disse databaser kan forskere analysere samarbejdsmønstre, karriereforløb og udviklingen af kreative partnerskaber. For eksempel kan netværksanalysemetoder anvendes til at identificere centrale figurer i branchen, hyppige samarbejdspartnere eller fremkomsten af nye talentklynger. Sådanne indsigter er værdifulde for at forstå dynamikken i kreativ produktion og de faktorer, der bidrager til succesfulde projekter.
Ud over data om rollebesætning og besætning giver IMDb-databaserne oplysninger om produktionsselskaber, genrer, udgivelsesdatoer og vurderinger, hvilket muliggør et holistisk syn på industrilandskabet. Filerne title.akas.tsv og title.crew.tsv beriger yderligere databasen ved at tilbyde alternative titler og detaljeret besætningsinformation. Denne omfattende datastruktur understøtter en bred vifte af analyser, fra diversitetsstudier til markedsudviklingsprognoser.
IMDb, ejet og drevet af Amazon, vedligeholder og opdaterer disse databaser regelmæssigt, hvilket sikrer, at brugerne har adgang til aktuelle og historiske oplysninger. Databaserne er frit tilgængelige til personlig og ikke-kommerciel brug, hvilket gør dem til en grundpille i ressourcerne for alle, der søger at udforske de komplekse netværk inden for underholdningsindustrien. For mere information og adgang til databaserne kan brugere besøge den officielle IMDb hjemmeside.
Anvendelser inden for maskinlæring og AI
IMDB-databaserne, kurateret og vedligeholdt af Internet Movie Database (IMDb), er blandt de mest anvendte ressourcer inden for maskinlæring og kunstig intelligens (AI) til forskning og udvikling. Disse databaser omfatter et bredt spektrum af information, herunder filmtitler, detaljer om rollebesætning og besætning, plotresuméer, brugervurderinger og genreklassifikationer. Deres strukturerede og omfattende karakter gør dem særligt værdifulde til en række AI-drevne applikationer.
En af de mest fremtrædende anvendelser af IMDB-databaser er inden for naturlig sprogbehandling (NLP), især til sentimentanalyse. IMDB Large Movie Review Dataset indeholder for eksempel tusindvis af bruger-genererede film anmeldelser mærket som positive eller negative, som fungerer som en benchmark for træning og evaluering af sentimentklassificeringsalgoritmer. Forskere bruger dette dataset til at udvikle og teste modeller, der kan automatisk fortolke og klassificere den følelse, der udtrykkes i tekstdata, en kapacitet, der strækker sig til bredere anvendelser som overvågning af sociale medier og analyse af kundefeedback.
Udover sentimentanalyse er IMDB-databaser essentielle til udviklingen af anbefalingssystemer. Ved at analysere brugervurderinger, visningshistorikker og filmmetadata kan maskinlæringsmodeller forudsige brugerpræferencer og foreslå relevant indhold. Denne tilgang understøtter de anbefalingsmotorer, der anvendes af store streamingplatforme, hvilket øger brugerengagement og tilfredshed. Diversiteten og omfanget af IMDB-data muliggør udforskningen af samarbejdskollektion, indhold-baseret filtrering og hybride anbefalingsteknikker.
IMDB-databaserne letter også forskning inden for opbygning af viden grafer og entitetsopløsning. De rige sammenhænge mellem film, skuespillere, instruktører og genrer giver et ideelt grundlag for at opbygge vidensgrafiker, der er essentielle for semantisk søgning, spørgsmålsbesvarelse og informationshentningssystemer. AI-modeller, der er trænet på disse grafer, kan besvare komplekse forespørgsler, såsom at identificere alle film, der har en bestemt skuespiller inden for en bestemt genre og tidsramme.
Derudover understøtter databaserne fremskridt inden for automatiseret indholdsmærkning, genreklassifikation og trendanalyse. Maskinlæringsalgoritmer kan trænes til at klassificere film i genrer baseret på plotresuméer eller til at registrere fremtrædende tendenser inden for filmproduktion og publikumspreferencer over tid. Disse indsigter er værdifulde for studier, marketingfolk og forskere, der søger at forstå og forudse skift i underholdningsindustrien.
Samlet set er IMDB-databaserne, der leveres af IMDb, grundlæggende for en bred vifte af maskinlæring og AI-applikationer, der driver innovation inden for sentimentanalyse, anbefalingssystemer, vidensrepræsentation og mere.
Begrænsninger, bias og overvejelser om datakvalitet
IMDb-databaserne, der leveres af IMDb, anvendes bredt til forskning, analyse og applikationsudvikling inden for filmstudier, datavidenskab og maskinlæring. Brugere skal dog være opmærksomme på flere begrænsninger, bias og datakvalitetsovervejelser, der er iboende i disse databaser.
En primær begrænsning er omfanget og fuldstændigheden af dataene. Selvom IMDb stræber efter at opretholde en omfattende database over film, tv-shows og relaterede personale, er databasen stort set crowd-sourced. Dette betyder, at inkluderingen og nøjagtigheden af oplysninger afhænger af brugerbidrag og redaktionel overvågning. Som følge heraf kan mindre kendte titler, produktioner på ikke-engelsk og uafhængige film være underrepræsenterede eller mangle detaljeret metadata. Desuden kan nogle datafelter – såsom plotresuméer, genretags eller rollebesætningslister – være ufuldstændige eller inkonsekvent formaterede på tværs af poster.
Bias er en anden vigtig overvejelse. IMDb-brugerbasen, der bidrager med vurderinger og anmeldelser, er ikke nødvendigvis repræsentativ for den globale befolkning. Demografiske skævheder – såsom alder, køn eller geografisk placering – kan påvirke aggregerede vurderinger og popularitetsmålinger. For eksempel kan film, der appellerer til yngre eller engelsktalende publikum, modtage uforholdsmæssigt høj synlighed og vurdering, mens værker fra andre regioner eller genrer kan blive overset. Dette introducerer en selektionsbias, der kan påvirke forskningsresultater eller algoritmiske anbefalinger bygget på IMDb-data.
Datakvaliteten påvirkes også af den dynamiske og udviklende natur af databasen. Poster opdateres ofte, rettes eller udvides, hvilket kan føre til inkonsekvenser over tid. For eksempel kan en films udgivelsesdato, rollebesætning eller vurdering ændre sig, når nye oplysninger bliver tilgængelige. Forskere, der bruger statiske snapshots af databasen, bør være forsigtige med temporale inkonsekvenser og sikre, at deres analyser tager højde for mulige opdateringer eller rettelser.
Desuden pålægges IMDb’s datalisens begrænsninger for brug, især for kommercielle applikationer. Databaserne stilles til rådighed for personlig og ikke-kommerciel brug, og brugerne skal overholde de vilkår, der er angivet af IMDb. Dette kan begrænse omfanget af projekter eller kræve yderligere tilladelser til bredere distribution.
Sammenfattende er IMDb-databaser en værdifuld ressource, men brugere skal kritisk vurdere deres fuldstændighed, potentielle bias og datakvalitetsproblemer. Omhyggelig overvejelse af disse faktorer er essentiel for ansvarlig og nøjagtig analyse, især i akademiske eller kommercielle sammenhænge.
Fremtidige retninger og nye anvendelsestilfælde
Fremtiden for IMDB-databaser formes af udviklende teknologier, udvidende brugerbehov og den voksende betydning af datadrevne indsigter i underholdningsindustrien. Som en af de mest omfattende og bredt brugte opbevaringssteder for film- og tv-metadata er IMDB-databaserne – vedligeholdt og distribueret af IMDb, et datterselskab af Amazon – klar til væsentlige fremskridt og nye anvendelser.
En vigtig retning er integrationen af IMDB-databaser med kunstig intelligens (AI) og maskinlærings (ML) systemer. Forskere og udviklere udnytter i stigende grad disse databaser til at træne anbefalingsmotorer, sentimentanalysemodeller og forudsigende analyseværktøjer. For eksempel, ved at kombinere IMDBs rige metadata med brugerinteraktionsdata kan streamingplatforme forbedre personaliserede indholdsforslag, optimere katalogcuration og forudsige publikumstrends. Som AI-modeller bliver mere sofistikerede, vil efterspørgslen efter granulære, opdaterede og velstrukturerede underholdningsdata kun stige.
En anden ny anvendelse er inden for naturlig sprogbehandling (NLP). IMDB’s omfattende samling af brugeranmeldelser, plotresuméer og castinformation giver et værdifuldt korpus til udvikling og benchmarking af NLP-algoritmer. Disse applikationer spænder fra automatiseret indholdmoderation og anmeldelsessammenfatning til ekstraktion af tematiske elementer og følelser over genrer og tidsperioder.
IMDB-databaserne finder også ny relevans inden for akademisk forskning og samfundsvidenskaberne. Forskere bruger dataene til at studere repræsentation, diversitet og kulturelle tendenser i medierne. Ved at analysere castdemografier, genreudvikling og internationale samarbejder kan forskere få indsigter i bredere samfundsmæssige skift og de globale dynamikker inden for underholdningsindustrien.
Ser vi frem, er det sandsynligt, at interoperabiliteten af IMDB-databaser med andre åbne data-initiativer vil udvide sig. At linke IMDB-data med kilder som Wikidata eller Library of Congress kan muliggøre rigere tværdomæneanalyser, hvilket understøtter projekter inden for digitale humaniora, videnopbygning og semantisk webudvikling.
Endelig, som underholdningslandskabet diversificeres med fremkomsten af nye medieformater – såsom webserier, podcasts og interaktivt indhold – er der et voksende behov for, at IMDB-databaserne udvikler sig og fanger disse nye former. Denne udvidelse vil sikre, at databaserne forbliver relevante og værdifulde for både brancheaktører og det bredere forskningssamfund.
Kilder & Referencer