Eine tiefgehende Analyse der IMDB-Datensätze: Enthüllung der Daten hinter der weltweit größten Filmdatenbank. Entdecken Sie, wie diese Datensätze die Filmanalytik und die Industrieforschung transformieren.
- Einführung in die IMDB-Datensätze und ihre Bedeutung
- Übersicht der verfügbaren IMDB-Datensatzdateien
- Datenstruktur und Schema erklärt
- Zugriff auf und Download von IMDB-Daten
- Bereinigung und Vorverarbeitung von IMDB-Datensätzen
- Analyse von Filmratings und -trends
- Erforschung von Besetzung, Crew und Branchennetzwerken
- Anwendungen in Machine Learning und KI
- Einschränkungen, Vorurteile und Überlegungen zur Datenqualität
- Zukünftige Richtungen und aufkommende Anwendungsfälle
- Quellen & Referenzen
Einführung in die IMDB-Datensätze und ihre Bedeutung
Die Internet Movie Database (IMDb) ist eine der umfassendsten und autoritativsten Quellen für Informationen über Filme, Fernsehsendungen, Videospiele und Streaming-Inhalte weltweit. Gegründet im Jahr 1990, hat sich IMDb zu einer Sammlung von Millionen von Titeln und Persönlichkeiten entwickelt und stellt eine wichtige Ressource für Branchenprofis, Forscher und Enthusiasten dar. Die IMDb-Datensätze sind kuratierte Sammlungen von strukturierten Daten, die aus der Hauptdatenbank von IMDb extrahiert wurden und für die öffentliche Nutzung unter speziellen Lizenzbedingungen zur Verfügung stehen. Diese Datensätze umfassen eine Vielzahl von Informationen, wie Filmtitel, Besetzungs- und Crewdetails, Veröffentlichungsdaten, Genre, Bewertungen und Benutzerbewertungen.
Die Bedeutung der IMDb-Datensätze liegt in ihrer Breite, Tiefe und Zuverlässigkeit. Da die Daten von IMDb, einer Tochtergesellschaft von Amazon, verwaltet und aktualisiert werden, profitieren sie von rigoroser Datenkurierung und einer großen Benutzerbasis, die zu ihrer Genauigkeit beiträgt. Forscher in Bereichen wie Datenwissenschaft, maschinelles Lernen, Sozialwissenschaften und digitale Geisteswissenschaften nutzen die IMDb-Datensätze, um Trends in der Medienproduktion und -nutzung zu analysieren, die Evolution von Genres zu studieren und Empfehlungssysteme zu entwickeln. Zum Beispiel werden die Datensätze häufig verwendet, um Algorithmen zu trainieren, die den Erfolg von Filmen vorhersagen, Zuschauerpräferenzen verstehen und die Karrieren von Schauspielern und Regisseuren kartieren.
Darüber hinaus fördert die offene Verfügbarkeit der IMDb-Datensätze Transparenz und Reproduzierbarkeit in der akademischen Forschung. Durch die Bereitstellung von standardisierten, maschinenlesbaren Daten ermöglicht IMDb Forschungsarbeiten, Ergebnisse zu validieren und auf früheren Arbeiten aufzubauen. Die Datensätze sind auch in Bildungsumgebungen von Bedeutung, wo Studenten lernen, mit realen Daten umzugehen und statistische oder rechnerische Techniken anzuwenden. Neben der Academia nutzen Fachleute der Industrie IMDb-Datensätze für Marktanalysen, Strategien zur Inhaltsakquise und Wettbewerbsbenchmarks.
Zusammenfassend lässt sich sagen, dass die IMDb-Datensätze eine grundlegende Ressource für alle darstellen, die die globale Unterhaltungslandschaft analysieren oder verstehen möchten. Ihr umfassender Umfang, regelmäßige Aktualisierungen und autoritative Herkunft machen sie unverzichtbar für eine Vielzahl analytischer, bildungsbezogener und kommerzieller Anwendungen. Während sich die Unterhaltungsindustrie weiterentwickelt, wird die Rolle von strukturierten, zugänglichen Daten wie die von IMDb bereitgestellten nur an Bedeutung gewinnen.
Übersicht der verfügbaren IMDB-Datensatzdateien
Die Internet Movie Database (IMDb) ist eine umfassende Online-Ressource für Informationen über Filme, Fernsehsendungen, Home-Videos, Videospiele und Streaming-Inhalte. Um Forschung, Datenanalyse und Anwendungsentwicklung zu unterstützen, bietet IMDb eine Auswahl herunterladbarer Datensätze an, die eine breite Palette von Daten aus der Unterhaltungsindustrie abdecken. Diese Datensätze werden im Rahmen der Initiative IMDb-Datensätze bereitgestellt, die darauf abzielt, die nichtkommerzielle Nutzung und akademische Forschung zu erleichtern.
Die IMDb-Datensätze werden als einfache Textdateien im Format Tab-Separated Values (TSV) verteilt, wodurch sie für die Verarbeitung mit einer Vielzahl von Datenanalysetools und Programmiersprachen zugänglich sind. Jede Datei konzentriert sich auf ein bestimmtes Aspekt der Datenbank, sodass Benutzer nur die für ihre Bedürfnisse relevanten Daten auswählen können. Die derzeit verfügbaren Hauptdatensatzdateien umfassen:
- title.basics.tsv.gz: Enthält grundlegende Informationen über Titel, wie Filme, TV-Serien und Episoden. Zu den wichtigsten Feldern gehören Titeltyp, primäre und originale Titel, Veröffentlichungsjahr, Laufzeit und Genre.
- title.akas.tsv.gz: Bietet alternative Titel für Werke, einschließlich regionaler und sprachspezifischer Variationen sowie Informationen über das Land und die Sprache jeder Titelversion.
- title.principals.tsv.gz: Listet die wichtigsten Besetzungen und die Crew für jeden Titel, einschließlich Schauspieler, Regisseure und Autoren, zusammen mit deren Rollen und Reihenfolgen.
- title.crew.tsv.gz: Details zu den Regisseuren und Autoren, die mit jedem Titel verbunden sind, unter Verwendung einzigartiger Identifizierer für jede Person.
- title.episode.tsv.gz: Enthält episodenspezifische Daten für TV-Serien, die Episoden mit ihren übergeordneten Serien verknüpfen und Saison- sowie Episodennummern bereitstellen.
- title.ratings.tsv.gz: Bietet von Nutzern generierte Bewertungen und die Anzahl der Stimmen für jeden Titel, die die Zuschauerresonanz widerspiegeln.
- name.basics.tsv.gz: Enthält Informationen über Personen in der Branche, wie Geburts- und Todesjahre, primäre Berufe und bekannte Titel.
Diese Datensätze werden regelmäßig aktualisiert, um die neuesten Informationen in der IMDb-Datenbank widerzuspiegeln. Der Zugang zu den Datensätzen ist für persönliche und nichtkommerzielle Nutzung vorgesehen, und die Nutzer sind verpflichtet, die Nutzungsbedingungen von IMDb zu beachten. Die Datensätze werden häufig in akademischen Forschungen, Projekten mit maschinellem Lernen und datengetriebenen Anwendungen verwendet, die strukturierte Informationen über die globale Unterhaltungsindustrie benötigen.
Datenstruktur und Schema erklärt
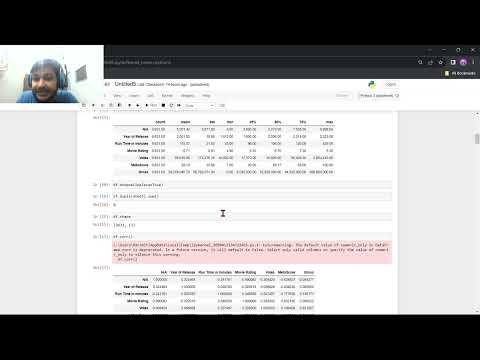
Die IMDb-Datensätze sind eine umfassende Sammlung von strukturierten Datendateien, die detaillierte Informationen über Filme, Fernsehsendungen, Videospiele und verwandte Entitäten bereitstellen. Diese Datensätze werden öffentlich von IMDb, einer Tochtergesellschaft von Amazon, zur Verfügung gestellt, die als eine der größten und autoritativsten Quellen für Film- und Fernsehmetadaten anerkannt ist. Die Datensätze werden hauptsächlich in Form von Tab-Separated Value (TSV)-Dateien verteilt, die jeweils einen bestimmten Aspekt des Unterhaltungsbereichs repräsentieren.
Jede IMDb-Datensatzdatei ist als Tabelle organisiert, wobei die Zeilen individuelle Datensätze und die Spalten bestimmte Attribute darstellen. Das Schema für jede Datei ist explizit definiert, um Konsistenz zu gewährleisten und automatisiertes Parsen zu erleichtern. Beispielsweise enthält die title.basics.tsv-Datei grundlegende Informationen über Titel, mit Spalten wie tconst (eine eindeutige Kennung für jeden Titel), titleType (z.B. Film, TV-Serie), primaryTitle, originalTitle, isAdult, startYear, endYear, runtimeMinutes und genres. Diese Struktur ermöglicht es den Benutzern, Titel basierend auf einer Vielzahl von Kriterien zu filtern und zu analysieren.
Weitere wichtige Dateien sind name.basics.tsv (enthält Informationen über Personen, wie Schauspieler, Regisseure und Autoren), title.crew.tsv (listet Regisseure und Autoren für jeden Titel auf), title.principals.tsv (gibt die wichtigsten Besetzungen und die Crew an) und title.ratings.tsv (stellt Benutzerbewertungen und Stimmenzahlen bereit). Jede Datei verwendet einen eindeutigen Identifizierer—wie tconst für Titel und nconst für Namen—um relationale Joins über Datensätze zu ermöglichen, die komplexe Abfragen und Datenintegration unterstützen.
Das Schema ist sowohl für Menschen lesbar als auch maschinenfreundlich gestaltet, wobei fehlende Werte durch den String N dargestellt werden. Dieser Ansatz stellt sicher, dass die Datensätze leicht in relationale Datenbanken, Datenanalysetools oder Programmierumgebungen für weitere Verarbeitungen importiert werden können. Die explizite Dokumentation des Schemas jeder Datei, einschließlich Datentypen und Feldbeschreibungen, wird von IMDb bereitgehalten, um Transparenz und Reproduzierbarkeit in der Forschung und Anwendungsentwicklung zu unterstützen.
Insgesamt machen das strukturierte Schema und die klare Datenorganisation der IMDb-Datensätze sie zu einer wertvollen Ressource für Datenwissenschaftler, Forscher und Entwickler, die daran interessiert sind, Trends, Beziehungen und Muster innerhalb der globalen Unterhaltungsindustrie zu erkunden.
Zugriff auf und Download von IMDB-Daten
Die Internet Movie Database (IMDb) ist eines der umfassendsten Repositorien für Informationen über Filme, Fernsehsendungen, Videospiele und verwandte Medien. Für Forscher, Entwickler und Dateninteressierte bietet IMDb eine Reihe von herunterladbaren Datensätzen, die eine umfassende Analyse und Anwendungsentwicklung ermöglichen. Diese Datensätze sind über die offizielle IMDb-Website zugänglich, die von IMDb.com, Inc., einer Tochtergesellschaft von Amazon.com, Inc., betrieben wird.
Der Zugriff auf IMDb-Datensätze ist unkompliziert. IMDb bietet einen speziellen Bereich für den Download von Datensätzen, bekannt als die IMDb-Datensatzseite. Hier finden Benutzer eine Sammlung von reinen Textdateien im Format Tab-Separated Values (TSV). Diese Dateien decken eine Vielzahl von Daten ab, einschließlich grundlegender Titelinformationen, Bewertungen, Besetzungs- und Crewdetails, Episodenleitfäden und mehr. Die Datensätze werden regelmäßig, typischerweise wöchentlich aktualisiert, um sicherzustellen, dass die Benutzer die aktuellsten verfügbaren Informationen erhalten.
Um die Datensätze herunterzuladen, müssen sich die Benutzer nicht registrieren oder anmelden. Die Dateien sind für persönliche und nichtkommerzielle Nutzung frei zugänglich, wie in den Lizenzbedingungen von IMDb festgelegt. Jede Datensatzdatei wird von einem Datenwörterbuch begleitet, das die Felder und deren Bedeutungen beschreibt, was für eine genaue Dateninterpretation und -integration unerlässlich ist. Die am häufigsten verwendeten Dateien sind:
- title.basics.tsv.gz: Enthält grundlegende Informationen über Filme, TV-Sendungen und Videospiele, wie Titel, Erscheinungsjahr und Genre.
- title.ratings.tsv.gz: Bietet IMDb-Benutzerbewertungen und Stimmenzahlen für jeden Titel.
- name.basics.tsv.gz: Listet wichtige Details über Personen in der Branche, einschließlich Schauspieler, Regisseure und Autoren.
- title.crew.tsv.gz: Gibt Details zu den Regisseuren und Autoren für jeden Titel an.
- title.principals.tsv.gz: Identifiziert die wichtigsten Besetzungen und die Crew für jeden Titel.
Nach dem Herunterladen können die komprimierten Dateien entpackt und mit gängigen Datenanalysetools oder Programmiersprachen wie Python oder R verarbeitet werden. Das offene Format und die klare Dokumentation machen die IMDb-Datensätze hochgradig zugänglich für eine Vielzahl von Forschungs- und Entwicklungszwecken. Die Benutzer sollten jedoch immer die Lizenzbedingungen überprüfen, um die Konformität mit den Nutzungsrichtlinien von IMDb sicherzustellen.
Für weitere Informationen und den Zugriff auf die Datensätze sollten die Benutzer direkt die offizielle IMDb-Website besuchen, die die autoritative Quelle für alle IMDb-Daten und -Dokumentationen bleibt.
Bereinigung und Vorverarbeitung von IMDB-Datensätzen
Die IMDB-Datensätze, bereitgestellt von IMDb, sind eine umfassende Ressource für Film- und Fernsehdaten, die häufig in akademischen Forschungen, Datenwissenschaft und Maschinenlernen-Projekten verwendet werden. Bevor diese Datensätze effektiv für Analysen oder Modelltraining genutzt werden können, ist eine gründliche Bereinigungs- und Vorverarbeitungsphase unerlässlich. Dieser Prozess gewährleistet Datenqualität, Konsistenz und Eignung für nachgelagerte Aufgaben.
IMDB-Datensätze werden typischerweise als Tab-Separated Value (TSV)-Dateien verteilt, die jeweils unterschiedliche Aspekte wie Titel, Bewertungen, Crew und Hauptbesetzungen darstellen. Der erste Schritt bei der Bereinigung besteht darin, mit fehlenden Werten umzugehen, die oft durch den String „N“ gekennzeichnet sind. Diese fehlenden Einträge können in Feldern wie Geburtsdaten, Sterbedaten oder sekundären Attributen auftreten. Abhängig von den Analysezielen können fehlende Werte imputiert, entfernt oder für eine besondere Behandlung markiert werden.
Ein weiterer kritischer Aspekt ist die Konvertierung von Datentypen. Viele Felder in den IMDB-Datensätzen, wie Jahr, Laufzeit und Bewertung, werden zunächst als Strings gelesen. Diese in geeignete numerische oder datetime-Formate zu konvertieren, ist notwendig für genaue Berechnungen und Analysen. Zum Beispiel sollten die Felder „startYear“ und „endYear“ als Ganzzahlen interpretiert werden, während „averageRating“ in eine Gleitkommazahl umgewandelt werden sollte.
Deduplication ist ebenfalls wichtig, da die Datenätze wiederholte Einträge aufgrund von Updates oder Zusammenführungen aus verschiedenen Datenquellen enthalten können. Sicherzustellen, dass jeder Film, jede Episode oder jede Person eindeutig repräsentiert ist, verhindert verzerrte Ergebnisse in statistischen Analysen oder Maschinenlernmodellen.
Die Normalisierung kategorischer Daten, wie Genres oder Berufe, ist ein weiterer wichtiger Vorverarbeitungsschritt. Die IMDB-Datensätze listen oft mehrere Genres oder Rollen in einem einzigen Feld auf, die durch Kommas getrennt sind. Diese in einzelne Kategorien aufzuteilen oder One-Hot-Encoding zu verwenden, kann eine granularere Analyse und Modelldatenbereitstellung erleichtern.
Schließlich ist das Verknüpfen mehrerer IMDB-Datensatzdateien eine gängige Vorverarbeitungsaufgabe. Beispielsweise ermöglicht das Verknüpfen der Datei „title.basics“ (die Filmmaterial enthält) mit „title.ratings“ (die Benutzerbewertungen enthält) über die eindeutige Kennung „tconst“ eine reichere, mehrdimensionale Analyse. Dabei muss darauf geachtet werden, die referenzielle Integrität sicherzustellen und Fälle zu behandeln, in denen Datensätze in einer Datei, aber nicht in einer anderen vorhanden sind.
Durch systematisches Angehen von fehlenden Werten, Datentypen, Duplikaten, kategorischer Normalisierung und Datensatzintegration können Forscher und Praktiker ungefilterte IMDB-Daten in ein sauberes, strukturiertes Format umwandeln, das bereit ist für fortgeschrittene Analysen und Anwendungen des maschinellen Lernens. Die offizielle IMDb-Website bietet detaillierte Dokumentationen und Schemadaten, um diese Vorverarbeitungsbemühungen zu unterstützen.
Analyse von Filmratings und -trends
Die Internet Movie Database (IMDb) ist eine der umfassendsten und autoritativsten Quellen für Informationen über Filme, Fernsehsendungen und verwandte Inhalte. Ihre Datensätze werden umfassend für die Analyse von Filmratings und -trends verwendet und bieten eine reichhaltige Ressource für Forscher, Datenwissenschaftler und Branchenprofis. Die IMDb-Datensätze sind öffentlich für nichtkommerzielle Nutzung verfügbar und werden regelmäßig aktualisiert, um die neuesten Informationen in der Unterhaltungsindustrie widerzuspiegeln.
Die IMDb-Datensätze umfassen eine Vielzahl von Dateien, die verschiedene Aspekte der Film- und Fernsehdaten abdecken. Zu den wichtigsten Datensätzen, die für die Analyse von Filmratings und -trends relevant sind, gehören:
- title.basics.tsv: Enthält grundlegende Informationen über Filme und TV-Sendungen, wie Titel, Veröffentlichungsjahr, Laufzeit und Genre.
- title.ratings.tsv: Bietet durchschnittliche Benutzerbewertungen und die Anzahl der Stimmen für jeden Titel, die für die Trendanalyse und das Verständnis von Zuschauerpräferenzen entscheidend sind.
- title.akas.tsv: Listet alternative Titel und internationale Versionen, die für länderübergreifende Analysen nützlich sind.
- name.basics.tsv: Enthält Daten zu Schauspielern, Regisseuren und anderen wichtigen Personen, was Studien über den Einfluss von Besetzung und Crew auf die Bewertungen ermöglicht.
Durch die Nutzung dieser Datensätze können Analytiker verfolgen, wie die Filmratings im Laufe der Zeit evolvieren, Muster in den Zuschauerpräferenzen identifizieren und Bewertungen mit Faktoren wie Genre, Erscheinungsjahr oder der Beteiligung bestimmter Schauspieler und Regisseure korrelieren. Zum Beispiel kann eine Zeitreihenanalyse der Datei title.ratings.tsv Trends in der Zuschauerauffassung aufzeigen, während das Querverweisen mit title.basics.tsv eine Segmentierung nach Genre oder Herkunftsland ermöglicht.
Die offene Verfügbarkeit der IMDb-Datensätze hat auch die Entwicklung von Modellen des maschinellen Lernens ermöglicht, um den Erfolg von Filmen vorherzusagen, die Sentimentanalyse von Benutzerbewertungen durchzuführen und die Netzwerkanalyse von Kooperationen innerhalb der Filmindustrie zu unterstützen. Diese Datensätze sind in der akademischen Forschung, der Branchenanalyse und bei Hobbyisten, die an Filmdaten interessiert sind, weit verbreitet.
IMDb wird von Amazon betrieben und sorgt für die Zuverlässigkeit und regelmäßige Aktualisierung ihrer Daten. Die Datensätze sind über die offizielle IMDb-Website zugänglich, und deren Struktur und Dokumentation werden aufrechterhalten, um ein breites Spektrum an analytischen Anwendungen zu unterstützen.
Zusammenfassend bieten die IMDb-Datensätze eine grundlegende Ressource zur Analyse von Filmratings und -trends und unterstützen sowohl quantitative als auch qualitative Forschungen über die Dynamik der globalen Unterhaltungsindustrie.
Erforschung von Besetzung, Crew und Branchennetzwerken
Die Internet Movie Database (IMDb) ist eine umfassende Online-Ressource für Informationen über Filme, Fernsehsendungen, Home-Videos, Videospiele und Streaming-Inhalte. Eine ihrer wertvollsten Ressourcen für Forscher und Branchenprofis ist die Suite der IMDb-Datensätze, die strukturierte Daten zu Besetzung, Crew und Branchennetzwerken bereitstellen. Diese Datensätze sind für nichtkommerzielle Nutzung verfügbar und werden häufig in akademischen Forschungen, Datenanalysen und in der Entwicklung von unterhaltungsbezogenen Anwendungen verwendet.
Die IMDb-Datensätze umfassen mehrere wichtige Dateien, die die Erforschung von Beziehungen zwischen Besetzung und Crew erleichtern. Die name.basics.tsv-Datei listet Personen auf, die in der Unterhaltungsindustrie tätig sind, einschließlich Schauspieler, Regisseure, Autoren und anderer Fachleute, zusammen mit ihren eindeutigen Kennungen, Geburts- und Sterbejahren sowie Hauptberufen. Die title.principals.tsv-Datei verbindet diese Personen mit bestimmten Titeln, detailliert deren Rollen (wie Schauspieler, Regisseur oder Produzent) und die Charaktere, die sie darstellen, oder die Funktionen, die sie ausführen. Diese relationale Struktur ermöglicht es den Nutzern, die beruflichen Netzwerke zu kartieren, die der Film- und Fernsehindustrie zugrunde liegen.
Durch die Nutzung dieser Datensätze können Forscher Muster der Zusammenarbeit, Karriereverläufe und die Entwicklung kreativer Partnerschaften analysieren. Beispielsweise können Netzwerkanalysetechniken verwendet werden, um zentrale Figuren innerhalb der Branche, häufige Kollaborateure oder das Auftauchen neuer Talentcluster zu identifizieren. Solche Einsichten sind wertvoll, um die Dynamik der kreativen Produktion und die Faktoren zu verstehen, die zu erfolgreichen Projekten beitragen.
Neben den Daten zu Besetzung und Crew bieten die IMDb-Datensätze Informationen über Produktionsunternehmen, Genres, Veröffentlichungsdaten und Bewertungen, die eine ganzheitliche Sicht auf die Branchenlandschaft ermöglichen. Die Dateien title.akas.tsv und title.crew.tsv bereichern den Datensatz weiter, indem sie alternative Titel und detaillierte Crewinformationen bereitstellen. Diese umfassende Datenstruktur unterstützt eine Vielzahl von Analysen, von Diversitätsstudien bis hin zu Markttrendprognosen.
IMDb, das von Amazon betrieben wird, aktualisiert diese Datensätze regelmäßig und stellt sicher, dass die Benutzer Zugang zu aktuellen und historischen Informationen haben. Die Datensätze sind für persönliche und nichtkommerzielle Nutzung frei zugänglich, was sie zu einer wichtigen Ressource für alle macht, die die komplexen Netzwerke der Unterhaltungsindustrie erkunden möchten. Für weitere Informationen und den Zugriff auf die Datensätze können die Benutzer die offizielle IMDb-Website besuchen.
Anwendungen in Machine Learning und KI
Die IMDB-Datensätze, die von der Internet Movie Database (IMDb) kuratiert und gepflegt werden, gehören zu den am häufigsten genutzten Ressourcen in den Bereichen Maschinenlernen und künstliche Intelligenz (KI) für Forschung und Entwicklung. Diese Datensätze umfassen ein breites Spektrum an Informationen, einschließlich Filmtitel, Besetzungs- und Crewdetails, Handlungszusammenfassungen, Benutzerbewertungen und Genreklassifikationen. Ihre strukturierte und umfassende Natur macht sie besonders wertvoll für eine Vielzahl von KI-gesteuerten Anwendungen.
Eine der prominentesten Anwendungen der IMDB-Datensätze ist in der natürlichen Sprachverarbeitung (NLP), insbesondere für Sentimentanalysen. Der IMDB Large Movie Review Dataset enthält beispielsweise Tausende von nutzergenerierten Filmrezensionen, die als positiv oder negativ gekennzeichnet sind, und dient als Benchmark für das Training und die Evaluierung von Sentiment-Klassifizierungsalgorithmen. Forscher nutzen diesen Datensatz, um Modelle zu entwickeln und zu testen, die automatisch die in Textdaten ausgedrückten Sinne interpretieren und klassifizieren können, eine Fähigkeit, die auf breitere Anwendungen wie das Monitoring von sozialen Medien und die Analyse von Kundenfeedback ausgeweitet werden kann.
Über die Sentimentanalyse hinaus sind IMDB-Datensätze auch instrumental bei der Entwicklung von Empfehlungssystemen. Durch die Analyse von Benutzerbewertungen, Viewing-Historien und Filmdaten können Maschinenlernmodelle Benutzerpräferenzen vorhersagen und relevante Inhalte vorschlagen. Dieser Ansatz bildet die Grundlage der Empfehlungssysteme, die von großen Streaming-Plattformen verwendet werden, um die Benutzerbindung und -zufriedenheit zu erhöhen. Die Vielfalt und der Umfang der IMDB-Daten ermöglichen die Erforschung von kollaborativem Filtern, inhaltsbasiertem Filtern und hybriden Empfehlungstechniken.
Die IMDB-Datensätze erleichtern auch die Forschung im Bereich des Wissensgraphaufbaus und der Entitätenauflösung. Die reichhaltigen Verbindungen zwischen Filmen, Schauspielern, Regisseuren und Genres bieten eine ideale Grundlage für den Aufbau von Wissensgraphen, die für semantische Suche, Fragenbeantwortung und Informationsabrufsysteme unerlässlich sind. KI-Modelle, die auf diesen Graphen trainiert werden, können komplexe Anfragen beantworten, wie zum Beispiel die Identifizierung aller Filme, die einen bestimmten Schauspieler innerhalb eines bestimmten Genres und Zeitrahmens zeigen.
Darüber hinaus unterstützen die Datensätze Fortschritte bei der automatisierten Inhaltsmarkierung, der Genreklassifikation und der Trendanalyse. Maschinenlernalgorithmen können trainiert werden, um Filme basierend auf Handlungszusammenfassungen in Genres zu klassifizieren oder aufkommende Trends in der Filmproduktion und Zuschauerpräferenzen im Laufe der Zeit zu erkennen. Diese Erkenntnisse sind wertvoll für Studios, Vermarkter und Forscher, die daran interessiert sind, Verschiebungen in der Unterhaltungsindustrie zu verstehen und vorherzusagen.
Insgesamt sind die IMDB-Datensätze, die von IMDb bereitgestellt werden, grundlegend für ein breites Spektrum an Anwendungen in den Bereichen maschinelles Lernen und KI, die Innovationen in der Sentimentanalyse, den Empfehlungssystemen, der Wissensdarstellung und darüber hinaus vorantreiben.
Einschränkungen, Vorurteile und Überlegungen zur Datenqualität
Die IMDb-Datensätze, bereitgestellt von IMDb, werden häufig für Forschung, Analytik und Anwendungsentwicklung in den Bereichen Filmwissenschaft, Datenwissenschaft und Maschinenlernen verwendet. Benutzer müssen sich jedoch der verschiedenen Einschränkungen, Vorurteile und Überlegungen zur Datenqualität bewusst sein, die diesen Datensätzen innewohnt.
Eine primäre Einschränkung ist der Umfang und die Vollständigkeit der Daten. Während IMDb bestrebt ist, eine umfassende Datenbank von Filmen, Fernsehsendungen und verwandten Personen zu führen, sind die Datensätze überwiegend crowdsourced. Dies bedeutet, dass die Einbeziehung und Genauigkeit von Informationen von den Benutzerbeiträgen und der redaktionellen Aufsicht abhängt. Infolgedessen können weniger bekannte Titel, nicht englischsprachige Produktionen und unabhängige Filme unterrepräsentiert oder mit unzureichenden Metadaten versehen sein. Außerdem können einige Datenfelder—wie Handlungszusammenfassungen, Genre-Tags oder Besetzungslisten—unvollständig oder inkonsistent formatiert sein.
Vorurteile sind ein weiterer wichtiger Aspekt. Die Benutzerbasis von IMDb, die Bewertungen und Rezensionen beiträgt, ist nicht unbedingt repräsentativ für die globale Bevölkerung. Demografische Verzerrungen—wie Alter, Geschlecht oder geografische Lage—können aggregierte Bewertungen und Popularitätskennzahlen beeinflussen. Zum Beispiel können Filme, die jüngeren oder englischsprachigen Zuschauern gefallen, unverhältnismäßig hohe Sichtbarkeit und Bewertungen erhalten, während Werke aus anderen Regionen oder Genres übersehen werden. Dies führt zu einer Auswahlverzerrung, die die Forschungsergebnisse oder algorithmischen Empfehlungen, die auf IMDb-Daten basieren, beeinflussen kann.
Die Datenqualität wird auch durch die dynamische und sich entwickelnde Natur der Datenbank beeinflusst. Einträge werden häufig aktualisiert, korrigiert oder erweitert, was zu Inkonsistenzen über die Zeit führen kann. Beispielsweise kann sich das Veröffentlichungsdatum, die Besetzung oder die Bewertung eines Films ändern, wenn neue Informationen verfügbar werden. Forscher, die statische Schnappschüsse des Datensatzes verwenden, sollten vorsichtig in Bezug auf zeitliche Inkonsistenzen sein und sicherstellen, dass ihre Analysen mögliche Updates oder Korrekturen berücksichtigen.
Darüber hinaus legt die Datenlizenzierung von IMDb Einschränkungen für die Nutzung, insbesondere für kommerzielle Anwendungen, fest. Die Datensätze werden für persönliche und nichtkommerzielle Nutzung bereitgestellt, und die Nutzer müssen die von IMDb festgelegten Bedingungen einhalten. Dies kann den Umfang von Projekten einschränken oder zusätzliche Genehmigungen für die breitere Implementierung erfordern.
Zusammenfassend lässt sich sagen, dass, obwohl die IMDb-Datensätze eine wertvolle Ressource darstellen, die Nutzer die Vollständigkeit, potenziellen Vorurteile und Datenqualitätsprobleme kritisch bewerten müssen. Eine sorgfältige Berücksichtigung dieser Faktoren ist unerlässlich für eine verantwortungsvolle und genaue Analyse, insbesondere in akademischen oder kommerziellen Kontexten.
Zukünftige Richtungen und aufkommende Anwendungsfälle
Die Zukunft der IMDB-Datensätze wird durch sich entwickelnde Technologien, steigende Benutzeranforderungen und die wachsende Bedeutung datengestützter Erkenntnisse in der Unterhaltungsindustrie geprägt. Als eines der umfassendsten und am häufigsten genutzten Archive für Film- und Fernsehdaten—die von IMDb, einer Tochtergesellschaft von Amazon, gepflegt und verteilt werden—stehen die IMDB-Datensätze vor bedeutenden Fortschritten und neuartigen Anwendungen.
Eine wichtige Richtung ist die Integration der IMDB-Datensätze mit Systemen der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML). Forscher und Entwickler nutzen zunehmend diese Datensätze, um Empfehlungssysteme, Sentimentanalysemodelle und prädiktive Analytik-Tools zu trainieren. Beispielsweise können Streaming-Plattformen durch die Kombination von IMDBs reichhaltigen Metadaten mit Benutzerdaten personalisierte Inhaltsvorschläge verfeinern, die Katalogkuration optimieren und Publikumstrends vorhersagen. Da KI-Modelle zunehmend komplexer werden, wird die Nachfrage nach granularen, aktuellen und gut strukturierten Unterhaltungsdaten weiter steigen.
Ein weiterer aufkommender Anwendungsfall liegt im Bereich der natürlichen Sprachverarbeitung (NLP). Die umfangreiche Sammlung von Benutzerbewertungen, Handlungszusammenfassungen und Besetzungsinformationen von IMDB bietet ein wertvolles Korpus für die Entwicklung und Benchmarking von NLP-Algorithmen. Diese Anwendungen reichen von automatisierter Inhaltsmoderation und Rezensionenzusammenfassungen bis hin zur Extraktion thematischer Elemente und Sentimenttrends über Genres und Zeiträume.
Die IMDB-Datensätze gewinnen auch neue Relevanz in akademischen Forschungen und Sozialwissenschaften. Wissenschaftler nutzen die Daten, um Repräsentation, Vielfalt und kulturelle Trends in den Medien zu untersuchen. Durch die Analyse von Besetzungsdemographien, Genre-Evolutionen und internationalen Kooperationen können Forscher Einblicke in breitere gesellschaftliche Verschiebungen und die globalen Dynamiken der Unterhaltungsindustrie gewinnen.
Ausblickend wird die Interoperabilität der IMDB-Datensätze mit anderen offenen Dateninitiativen voraussichtlich zunehmen. Die Verknüpfung von IMDB-Daten mit Quellen wie Wikidata oder der Library of Congress kann reichhaltigere bereichsübergreifende Analysen ermöglichen und Projekte in den digitalen Geisteswissenschaften, beim Wissensgraphaufbau und in der semantischen Webentwicklung unterstützen.
Abschließend wird es mit der Diversifizierung der Unterhaltungslandschaft durch das Aufkommen neuer Medienformate—wie Web-Serien, Podcasts und interaktiven Inhalten—eine zunehmende Notwendigkeit geben, dass die IMDB-Daten sichtbar bleiben und diese aufkommenden Formen erfassen. Diese Erweiterung wird sicherstellen, dass die Datensätze sowohl für die Branchenanwender als auch für die breitere Forschungsgemeinschaft weiterhin relevant und wertvoll bleiben.
Quellen & Referenzen