Uma Análise Profunda dos Conjuntos de Dados do IMDB: Revelando os Dados por Trás do Maior Banco de Dados de Filmes do Mundo. Descubra Como Esses Conjuntos de Dados Transformam a Análise Cinematográfica e a Pesquisa da Indústria.
- Introdução aos Conjuntos de Dados do IMDB e sua Significância
- Visão Geral dos Arquivos Disponíveis do Conjunto de Dados do IMDB
- Estrutura e Esquema dos Dados Explicados
- Acessando e Baixando Dados do IMDB
- Limpeza e Preprocessamento dos Conjuntos de Dados do IMDB
- Analisando Classificações e Tendências de Filmes
- Explorando Elencos, Equipes e Redes da Indústria
- Aplicações em Aprendizagem de Máquina e IA
- Limitações, Bias e Considerações sobre a Qualidade dos Dados
- Direções Futuras e Casos de Uso Emergentes
- Fontes & Referências
Introdução aos Conjuntos de Dados do IMDB e sua Significância
O Internet Movie Database (IMDb) é uma das fontes mais abrangentes e autoritativas do mundo para informações relacionadas a filmes, programas de televisão, videogames e conteúdo de streaming. Fundado em 1990, o IMDb cresceu para englobar milhões de títulos e personalidades, servindo como um recurso crítico para profissionais da indústria, pesquisadores e entusiastas. Os Conjuntos de Dados do IMDb são coleções organizadas de dados estruturados extraídos do banco de dados principal do IMDb, disponibilizados para uso público sob termos de licenciamento específicos. Esses conjuntos de dados incluem uma ampla gama de informações, como títulos de filmes, detalhes de elencos e equipes, datas de lançamento, gêneros, classificações e avaliações de usuários.
A significância dos Conjuntos de Dados do IMDb reside em sua amplitude, profundidade e confiabilidade. Como os dados são mantidos e atualizados pelo IMDb, uma subsidiária da Amazon, eles se beneficiam de uma curadoria rigorosa de dados e de uma vasta base de usuários contribuindo para sua precisão. Pesquisadores em campos como ciência de dados, aprendizado de máquina, ciências sociais e humanidades digitais utilizam os Conjuntos de Dados do IMDb para analisar tendências na produção e consumo de mídia, estudar a evolução de gêneros e desenvolver sistemas de recomendação. Por exemplo, os conjuntos de dados são frequentemente utilizados para treinar algoritmos para prever o sucesso de filmes, entender as preferências do público e mapear as carreiras de atores e diretores.
Além disso, a disponibilidade aberta dos Conjuntos de Dados do IMDb promove a transparência e a reprodutibilidade na pesquisa acadêmica. Ao fornecer dados padronizados e legíveis por máquina, o IMDb permite que os pesquisadores validem descobertas e construam sobre trabalhos anteriores. Os conjuntos de dados também são fundamentais em ambientes educacionais, onde os alunos aprendem a manipular dados do mundo real e aplicar técnicas estatísticas ou computacionais. Além da academia, profissionais da indústria aproveitam os Conjuntos de Dados do IMDb para análises de mercado, estratégias de aquisição de conteúdo e benchmarking competitivo.
Em resumo, os Conjuntos de Dados do IMDb representam um recurso fundamental para qualquer pessoa que busca analisar ou entender o panorama global do entretenimento. Sua abrangência, atualizações regulares e procedência autoritária os tornam indispensáveis para uma ampla gama de aplicações analíticas, educacionais e comerciais. À medida que a indústria do entretenimento continua a evoluir, o papel de dados estruturados e acessíveis, como os fornecidos pelo IMDb, só crescerá em importância.
Visão Geral dos Arquivos Disponíveis do Conjunto de Dados do IMDB
O Internet Movie Database (IMDb) é um recurso online abrangente para informações relacionadas a filmes, programas de televisão, vídeos caseiros, videogames e conteúdo de streaming. Para apoiar pesquisa, análise de dados e desenvolvimento de aplicações, IMDb fornece uma seleção de conjuntos de dados baixáveis que cobrem uma ampla gama de dados da indústria do entretenimento. Esses conjuntos de dados são disponibilizados por meio da iniciativa Conjuntos de Dados do IMDb, que visa facilitar o uso não comercial e a pesquisa acadêmica.
Os conjuntos de dados do IMDb são distribuídos como arquivos de texto simples no formato de valores separados por tabulação (TSV), tornando-os acessíveis para processamento com uma variedade de ferramentas de análise de dados e linguagens de programação. Cada arquivo foca em um aspecto específico do banco de dados, permitindo que os usuários selecionem apenas os dados relevantes para suas necessidades. Os principais arquivos de dados atualmente disponíveis incluem:
- title.basics.tsv.gz: Contém informações essenciais sobre títulos, como filmes, séries de TV e episódios. Os campos principais incluem tipo de título, títulos primários e originais, ano de lançamento, duração e gênero.
- title.akas.tsv.gz: Fornece títulos alternativos para obras, incluindo variações regionais e específicas de idioma, bem como informações sobre o país e o idioma de cada versão do título.
- title.principals.tsv.gz: Lista o elenco e a equipe principal para cada título, incluindo atores, diretores e roteiristas, juntamente com seus papéis e ordenação.
- title.crew.tsv.gz: Detalha os diretores e roteiristas associados a cada título, usando identificadores únicos para cada pessoa.
- title.episode.tsv.gz: Contém dados ao nível de episódio para séries de TV, ligando episódios a suas séries parentais e fornecendo números de temporada e episódio.
- title.ratings.tsv.gz: Oferece classificações geradas por usuários e o número de votos para cada título, refletindo a recepção do público.
- name.basics.tsv.gz: Inclui informações sobre pessoas da indústria, como anos de nascimento e morte, profissões principais e títulos conhecidos.
Esses conjuntos de dados são atualizados regularmente para refletir as informações mais recentes no banco de dados do IMDb. O acesso aos conjuntos de dados é fornecido para uso pessoal e não comercial, e os usuários devem cumprir os termos de uso especificados pelo IMDb. Os conjuntos de dados são amplamente utilizados em pesquisas acadêmicas, projetos de aprendizado de máquina e aplicações orientadas a dados que requerem informações estruturadas sobre a indústria global de entretenimento.
Estrutura e Esquema dos Dados Explicados
Os conjuntos de dados do IMDb são uma coleção abrangente de arquivos de dados estruturados que fornecem informações detalhadas sobre filmes, programas de televisão, videogames e entidades relacionadas. Esses conjuntos de dados são disponibilizados publicamente pelo IMDb, uma subsidiária da Amazon, que é reconhecida como uma das maiores e mais autoritativas fontes de metadados de filmes e televisão do mundo. Os conjuntos de dados são principalmente distribuídos na forma de arquivos de valores separados por tabulação (TSV), cada um representando um aspecto específico do domínio do entretenimento.
Cada arquivo de conjunto de dados do IMDb é organizado como uma tabela, com linhas representando registros individuais e colunas correspondendo a atributos específicos. O esquema para cada arquivo é explicitamente definido, garantindo consistência e facilitando a análise automatizada. Por exemplo, o arquivo title.basics.tsv contém informações centrais sobre títulos, com colunas como tconst (um identificador único para cada título), titleType (por exemplo, filme, série de TV), primaryTitle, originalTitle, isAdult, startYear, endYear, runtimeMinutes e genres. Essa estrutura permite que os usuários filtrem e analisem títulos com base em uma ampla gama de critérios.
Outros arquivos-chave incluem name.basics.tsv (contendo informações sobre pessoas, como atores, diretores e roteiristas), title.crew.tsv (listando diretores e roteiristas para cada título), title.principals.tsv (detalhando elenco e equipe principal) e title.ratings.tsv (fornecendo classificações de usuários e contagem de votos). Cada arquivo usa um identificador exclusivo—como tconst para títulos e nconst para nomes—para permitir junções relacionais entre conjuntos de dados, suportando consultas complexas e integração de dados.
O esquema é projetado para ser legível por humanos e amigável para máquinas, com valores ausentes representados pela string N. Essa abordagem garante que os conjuntos de dados possam ser facilmente importados para bancos de dados relacionais, ferramentas de análise de dados, ou ambientes de programação para processamento adicional. A documentação explícita do esquema de cada arquivo, incluindo tipos de dados e descrições de campo, é mantida pelo IMDb para apoiar a transparência e reprodutibilidade na pesquisa e desenvolvimento de aplicações.
Em geral, o esquema estruturado e a clara organização de dados dos conjuntos de dados do IMDb fazem deles um recurso valioso para cientistas de dados, pesquisadores e desenvolvedores interessados em explorar tendências, relações e padrões dentro da indústria global do entretenimento.
Acessando e Baixando Dados do IMDB
O Internet Movie Database (IMDb) é um dos repositórios mais abrangentes do mundo para informações relacionadas a filmes, programas de televisão, videogames e mídia relacionada. Para pesquisadores, desenvolvedores e entusiastas de dados, o IMDb fornece um conjunto de conjuntos de dados baixáveis que possibilitam análise em larga escala e desenvolvimento de aplicações. Esses conjuntos de dados são disponibilizados através do site oficial do IMDb, operado pela IMDb.com, Inc., uma subsidiária da Amazon.com, Inc.
Acessar os conjuntos de dados do IMDb é simples. O IMDb oferece uma seção dedicada para downloads de conjuntos de dados, conhecida como a página de Conjuntos de Dados do IMDb. Aqui, os usuários podem encontrar uma coleção de arquivos de texto puro no formato de valores separados por tabulação (TSV). Esses arquivos cobrem uma ampla gama de dados, incluindo informações básicas sobre títulos, classificações, detalhes de elencos e equipes, guias de episódios e muito mais. Os conjuntos de dados são atualizados regularmente, tipicamente em uma base semanal, garantindo que os usuários tenham acesso às informações mais atuais disponíveis.
Para baixar os conjuntos de dados, os usuários não precisam se registrar ou fazer login. Os arquivos são acessíveis gratuitamente para uso pessoal e não comercial, conforme especificado nos termos de licenciamento do IMDb. Cada arquivo de conjunto de dados é acompanhado por um dicionário de dados que descreve os campos e seus significados, o que é essencial para interpretação e integração precisas dos dados. Os arquivos mais comumente utilizados incluem:
- title.basics.tsv.gz: Contém informações essenciais sobre filmes, programas de TV e videogames, como título, ano de lançamento e gênero.
- title.ratings.tsv.gz: Fornece classificações e contagens de votos dos usuários do IMDb para cada título.
- name.basics.tsv.gz: Lista detalhes-chave sobre pessoas na indústria, incluindo atores, diretores e roteiristas.
- title.crew.tsv.gz: Detalha os diretores e roteiristas de cada título.
- title.principals.tsv.gz: Identifica o elenco e a equipe principal de cada título.
Após o download, os arquivos compactados podem ser extraídos e processados usando ferramentas padrão de análise de dados ou linguagens de programação como Python ou R. O formato aberto e a documentação clara tornam os conjuntos de dados do IMDb altamente acessíveis para uma variedade de propósitos de pesquisa e desenvolvimento. No entanto, os usuários devem sempre revisar os termos de licenciamento para garantir a conformidade com as políticas de uso do IMDb.
Para mais informações e para acessar os conjuntos de dados, os usuários devem consultar diretamente o site oficial do IMDb, que continua sendo a fonte autoritativa para todos os dados e documentação do IMDb.
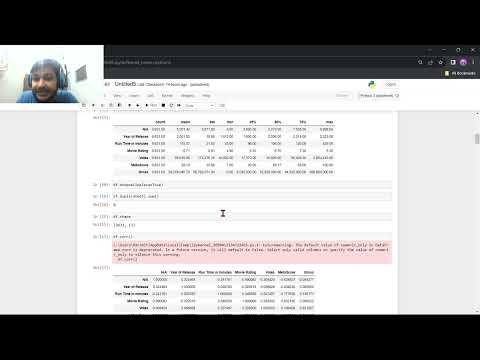
Limpeza e Preprocessamento dos Conjuntos de Dados do IMDB
Os Conjuntos de Dados do IMDB, fornecidos pelo IMDb, são um recurso abrangente para dados de filmes e televisão, amplamente utilizados em pesquisa acadêmica, ciência de dados e projetos de aprendizado de máquina. Antes que esses conjuntos de dados possam ser utilizados efetivamente para análise ou treinamento de modelos, uma fase de limpeza e preprocessamento é essencial. Este processo garante a qualidade dos dados, a consistência e a adequação para tarefas subsequentes.
Os conjuntos de dados do IMDB são normalmente distribuídos como arquivos de valores separados por tabulação (TSV), cada um representando diferentes aspectos como títulos, classificações, equipe e elenco principal. O primeiro passo na limpeza envolve lidar com valores ausentes, que geralmente são denotados pela string “N”. Essas entradas ausentes podem aparecer em campos como datas de nascimento, datas de morte ou atributos secundários. Dependendo dos objetivos de análise, os valores ausentes podem ser imputados, removidos ou sinalizados para tratamento especial.
Outro aspecto crítico é a conversão de tipos de dados. Muitos campos nos conjuntos de dados do IMDB, como ano, duração e classificação, são inicialmente lidos como strings. Converter esses para formatos numéricos ou de data/hora apropriados é necessário para cálculos e análises precisas. Por exemplo, os campos “startYear” e “endYear” devem ser analisados como inteiros, enquanto “averageRating” deve ser convertido para um número de ponto flutuante.
A deduplicação também é importante, pois os conjuntos de dados podem conter entradas repetidas devido a atualizações ou fusões de diferentes fontes de dados. Garantir que cada filme, episódio ou pessoa seja representado de forma única previne resultados distorcidos em análises estatísticas ou modelos de aprendizado de máquina.
A normalização de dados categóricos, como gêneros ou profissões, é outro passo-chave no preprocessamento. Os conjuntos de dados do IMDB frequentemente listam múltiplos gêneros ou papéis em um único campo, separados por vírgulas. Dividir esses em categorias individuais ou usar codificação one-hot pode facilitar uma análise mais granular e entrada para modelos.
Por fim, unir vários arquivos de conjuntos de dados do IMDB é uma tarefa comum de preprocessamento. Por exemplo, linkar o arquivo “title.basics” (contendo metadados de filmes) com “title.ratings” (contendo classificações de usuários) por meio do identificador único “tconst” permite análises ricas e multidimensionais. É preciso ter cuidado para garantir integridade referencial e lidar com casos onde registros existem em um arquivo, mas não em outro.
Ao abordar sistematicamente valores ausentes, tipos de dados, duplicatas, normalização categórica e integração de conjuntos de dados, pesquisadores e praticantes podem transformar dados brutos do IMDB em um formato limpo e estruturado, prontos para análises avançadas e aplicações de aprendizado de máquina. O site oficial do IMDb fornece documentação detalhada e descrições de esquemas para orientar esses esforços de preprocessamento.
Analisando Classificações e Tendências de Filmes
O Internet Movie Database (IMDb) é uma das fontes mais abrangentes e autoritativas do mundo para informações sobre filmes, programas de televisão e conteúdos relacionados. Seus conjuntos de dados são amplamente utilizados para analisar classificações de filmes e tendências, oferecendo um rico recurso para pesquisadores, cientistas de dados e profissionais da indústria. Os conjuntos de dados do IMDb são disponibilizados publicamente para uso não comercial e são atualizados regularmente para refletir as informações mais recentes na indústria do entretenimento.
Os conjuntos de dados do IMDb incluem uma variedade de arquivos que cobrem diferentes aspectos dos dados de filmes e televisão. Os principais conjuntos de dados relevantes para analisar classificações de filmes e tendências incluem:
- title.basics.tsv: Contém informações essenciais sobre filmes e programas de TV, como título, ano de lançamento, duração e gênero.
- title.ratings.tsv: Fornece classificações médias de usuários e o número de votos para cada título, que são cruciais para análise de tendências e compreensão das preferências do público.
- title.akas.tsv: Lista títulos alternativos e versões internacionais, úteis para análise de mercado cruzado.
- name.basics.tsv: Inclui dados sobre atores, diretores e outros profissionais-chave, permitindo estudos sobre o impacto do elenco e equipe nas classificações.
Ao aproveitar esses conjuntos de dados, os analistas podem acompanhar como as classificações dos filmes evoluem ao longo do tempo, identificar padrões nas preferências do público e correlacionar classificações com fatores como gênero, ano de lançamento ou a participação de atores e diretores específicos. Por exemplo, a análise de séries temporais do arquivo title.ratings.tsv pode revelar tendências no sentimento do público, enquanto a referência cruzada com title.basics.tsv permite segmentação por gênero ou país de origem.
A disponibilidade aberta dos conjuntos de dados do IMDb também facilitou o desenvolvimento de modelos de aprendizado de máquina para prever o sucesso de filmes, análise de sentimento de avaliações de usuários e análise de rede de colaborações dentro da indústria cinematográfica. Esses conjuntos de dados são amplamente utilizados em pesquisa acadêmica, análises da indústria e por hobbyistas interessados em dados de filmes.
O IMDb pertence e é operado pela Amazon, o que garante a confiabilidade e a atualização regular de seus dados. Os conjuntos de dados são acessíveis através do site oficial do IMDb, e sua estrutura e documentação são mantidas para suportar uma ampla gama de aplicações analíticas.
Em resumo, os conjuntos de dados do IMDb fornecem um recurso fundamental para analisar classificações e tendências de filmes, apoiando tanto a pesquisa quantitativa quanto qualitativa sobre as dinâmicas da indústria global do entretenimento.
Explorando Elencos, Equipes e Redes da Indústria
O Internet Movie Database (IMDb) é um recurso online abrangente para informações relacionadas a filmes, programas de televisão, vídeos caseiros, videogames e conteúdo de streaming. Um dos seus ativos mais valiosos para pesquisadores e profissionais da indústria é a suíte de Conjuntos de Dados do IMDb, que fornece dados estruturados sobre elencos, equipes e redes da indústria. Esses conjuntos de dados são disponibilizados para uso não comercial e são amplamente utilizados em pesquisa acadêmica, análise de dados e desenvolvimento de aplicações relacionadas ao entretenimento.
Os Conjuntos de Dados do IMDb incluem vários arquivos-chave que facilitam a exploração de relacionamentos entre elencos e equipes. O arquivo name.basics.tsv lista indivíduos envolvidos na indústria do entretenimento, incluindo atores, diretores, roteiristas e outros profissionais, juntamente com seus identificadores únicos, anos de nascimento e morte, e profissões principais. O arquivo title.principals.tsv conecta esses indivíduos a títulos específicos, detalhando seus papéis (como ator, diretor ou produtor) e os personagens que interpretam ou as funções que desempenham. Essa estrutura relacional permite que os usuários mapeiem as redes profissionais que sustentam as indústrias de filmes e televisão.
Ao aproveitar esses conjuntos de dados, pesquisadores podem analisar padrões de colaboração, trajetórias de carreira e a evolução de parcerias criativas. Por exemplo, técnicas de análise de rede podem ser aplicadas para identificar figuras centrais dentro da indústria, colaboradores frequentes ou o surgimento de novos clusters de talentos. Esses insights são valiosos para entender as dinâmicas da produção criativa e os fatores que contribuem para projetos bem-sucedidos.
Além dos dados de elencos e equipes, os Conjuntos de Dados do IMDb fornecem informações sobre empresas de produção, gêneros, datas de lançamento e classificações, permitindo uma visão holística do panorama da indústria. Os arquivos title.akas.tsv e title.crew.tsv enriquecem ainda mais o conjunto de dados ao oferecer títulos alternativos e informações detalhadas sobre a equipe, respectivamente. Essa estrutura de dados abrangente suporta uma ampla gama de análises, desde estudos de diversidade até previsão de tendências de mercado.
O IMDb, pertencente e operado pela Amazon, mantém e atualiza esses conjuntos de dados regularmente, garantindo que os usuários tenham acesso a informações atuais e históricas. Os conjuntos de dados são acessíveis gratuitamente para uso pessoal e não comercial, tornando-se um recurso fundamental para quem busca explorar as intricadas redes da indústria do entretenimento. Para mais informações e acesso aos conjuntos de dados, os usuários podem visitar o site oficial do IMDb.
Aplicações em Aprendizagem de Máquina e IA
Os conjuntos de dados do IMDB, curados e mantidos pelo Internet Movie Database (IMDb), estão entre os recursos mais amplamente utilizados nas áreas de aprendizado de máquina e inteligência artificial (IA) para pesquisa e desenvolvimento. Esses conjuntos de dados abrangem um amplo espectro de informações, incluindo títulos de filmes, detalhes de elenco e equipe, resumos de enredos, avaliações de usuários e classificações de gênero. Sua natureza estruturada e abrangente os torna particularmente valiosos para uma variedade de aplicações impulsionadas por IA.
Um dos usos mais proeminentes dos conjuntos de dados do IMDB é em processamento de linguagem natural (PLN), especialmente para análise de sentimento. O Conjunto de Dados de Avaliação de Cinema Grande do IMDB, por exemplo, contém milhares de avaliações de filmes geradas por usuários rotuladas como positivas ou negativas, servindo como referência para treinar e avaliar algoritmos de classificação de sentimento. Pesquisadores aproveitam esse conjunto de dados para desenvolver e testar modelos que podem interpretar e classificar automaticamente o sentimento expresso em dados textuais, uma capacidade que se estende a aplicações mais amplas, como monitoramento de mídias sociais e análise de feedback de clientes.
Além da análise de sentimento, os conjuntos de dados do IMDB são instrumentais no desenvolvimento de sistemas de recomendação. Ao analisar classificações de usuários, históricos de visualização e metadados de filmes, modelos de aprendizado de máquina podem prever as preferências dos usuários e sugerir conteúdos relevantes. Essa abordagem fundamenta os mecanismos de recomendação usados por plataformas de streaming importantes, aprimorando o envolvimento e a satisfação do usuário. A diversidade e a escala dos dados do IMDB permitem a exploração de filtragem colaborativa, filtragem baseada em conteúdo e técnicas de recomendação híbrida.
Os conjuntos de dados do IMDB também facilitam a pesquisa na construção de grafos de conhecimento e resolução de entidades. As ricas interconexões entre filmes, atores, diretores e gêneros fornecem uma base ideal para a construção de grafos de conhecimento, que são essenciais para busca semântica, resposta a perguntas e sistemas de recuperação de informação. Modelos de IA treinados nesses grafos podem responder a consultas complexas, como identificar todos os filmes com um determinado ator dentro de um gênero e período de tempo específicos.
Além disso, os conjuntos de dados suportam avanços na marcação automática de conteúdo, classificação de gênero e análise de tendências. Algoritmos de aprendizado de máquina podem ser treinados para classificar filmes em gêneros com base em resumos de enredos ou detectar tendências emergentes na produção de filmes e preferências do público ao longo do tempo. Esses insights são valiosos para estúdios, profissionais de marketing e pesquisadores que buscam entender e antecipar mudanças na indústria de entretenimento.
Em geral, os conjuntos de dados do IMDB, fornecidos pelo IMDb, são fundamentais para uma vasta gama de aplicações de aprendizado de máquina e IA, impulsionando inovações em análise de sentimento, sistemas de recomendação, representação do conhecimento e muito mais.
Limitações, Bias e Considerações sobre a Qualidade dos Dados
Os conjuntos de dados do IMDb, fornecidos pelo IMDb, são amplamente utilizados para pesquisa, análises e desenvolvimento de aplicações nas áreas de estudos cinematográficos, ciência de dados e aprendizado de máquina. No entanto, os usuários devem estar cientes de várias limitações, vieses e considerações sobre a qualidade dos dados inerentes a esses conjuntos de dados.
Uma limitação principal é a abrangência e a completude dos dados. Embora o IMDb se esforce para manter um banco de dados abrangente de filmes, programas de televisão e pessoal relacionado, o conjunto de dados é em grande parte crowdsourced. Isso significa que a inclusão e precisão das informações dependem de contribuições dos usuários e supervisão editorial. Como resultado, títulos menos conhecidos, produções em idiomas não ingleses e filmes independentes podem estar sub-representados ou carecer de metadados detalhados. Além disso, alguns campos de dados—como resumos de enredos, tags de gênero ou listas de elenco—podem estar incompletos ou formatados de maneira inconsistente entre as entradas.
O viés é outra consideração importante. A base de usuários do IMDb, que contribui com classificações e avaliações, pode não ser representativa da população global. Vieses demográficos—como idade, gênero ou localização geográfica—podem influenciar as classificações agregadas e as métricas de popularidade. Por exemplo, filmes que atraem públicos mais jovens ou anglófonos podem receber visibilidade e classificações desproporcionalmente altas, enquanto obras de outras regiões ou gêneros podem ser negligenciadas. Isso introduz um viés de seleção que pode afetar resultados de pesquisa ou recomendações algorítmicas baseadas em dados do IMDb.
A qualidade dos dados também é afetada pela natureza dinâmica e em evolução do banco de dados. As entradas são frequentemente atualizadas, corrigidas ou expandidas, o que pode levar a inconsistências ao longo do tempo. Por exemplo, a data de lançamento de um filme, o elenco ou a classificação podem mudar à medida que novas informações se tornam disponíveis. Pesquisadores que utilizam instantâneas estáticas do conjunto de dados devem ter cautela com inconsistências temporais e garantir que suas análises levem em conta possíveis atualizações ou correções.
Além disso, o licenciamento de dados do IMDb impõe restrições ao uso, especialmente para aplicações comerciais. Os conjuntos de dados são fornecidos para uso pessoal e não comercial, e os usuários devem cumprir os termos descritos pelo IMDb. Isso pode limitar a abrangência de projetos ou exigir permissões adicionais para implementações mais amplas.
Em resumo, embora os conjuntos de dados do IMDb sejam um recurso valioso, os usuários devem avaliar criticamente sua completude, potenciais vieses e problemas de qualidade dos dados. A cuidadosa consideração desses fatores é essencial para uma análise responsável e precisa, especialmente em contextos acadêmicos ou comerciais.
Direções Futuras e Casos de Uso Emergentes
O futuro dos conjuntos de dados do IMDB é moldado por tecnologias em evolução, necessidades de usuários em expansão e a crescente importância de insights orientados a dados na indústria do entretenimento. Como um dos repositórios mais abrangentes e amplamente utilizados de metadados de filmes e televisão, os conjuntos de dados do IMDB—mantidos e distribuídos pelo IMDb, uma subsidiária da Amazon—estão prontos para avanços significativos e novas aplicações.
Uma direção chave é a integração dos conjuntos de dados do IMDB com sistemas de inteligência artificial (IA) e aprendizado de máquina (ML). Pesquisadores e desenvolvedores estão cada vez mais aproveitando esses conjuntos de dados para treinar motores de recomendação, modelos de análise de sentimento e ferramentas de análises preditivas. Por exemplo, ao combinar os ricos metadados do IMDB com dados de interação do usuário, plataformas de streaming podem refinar sugestões de conteúdos personalizados, otimizar a curadoria de catálogos e prever tendências do público. À medida que os modelos de IA se tornam mais sofisticados, a demanda por dados de entretenimento granular, atualizados e bem estruturados só aumentará.
Outro caso de uso emergente está no campo do processamento de linguagem natural (PLN). A extensa coleção de avaliações de usuários, resumos de enredos e informações sobre elencos do IMDB fornece um valioso corpus para desenvolvimento e benchmark de algoritmos de PLN. Essas aplicações variam desde moderação automática de conteúdo e resumo de avaliações até extração de elementos temáticos e tendências de sentimento por gêneros e períodos de tempo.
Os conjuntos de dados do IMDB também estão ganhando nova relevância em pesquisa acadêmica e ciências sociais. Pesquisadores estão utilizando os dados para estudar representação, diversidade e tendências culturais na mídia. Ao analisar demografia do elenco, evolução do gênero e colaborações internacionais, os pesquisadores podem obter insights sobre mudanças sociais mais amplas e as dinâmicas globais da indústria do entretenimento.
Olhando para o futuro, a interoperabilidade dos conjuntos de dados do IMDB com outras iniciativas de dados abertos provavelmente se expandirá. Vincular dados do IMDB com fontes como Wikidata pode permitir análises cruzadas mais ricas, apoiando projetos em humanidades digitais, construção de grafos de conhecimento e desenvolvimento da web semântica.
Por fim, à medida que o panorama do entretenimento se diversifica com o surgimento de novos formatos de mídia—como web séries, podcasts e conteúdo interativo—há uma crescente necessidade de que os conjuntos de dados do IMDB evoluam e capturem essas formas emergentes. Essa expansão garantirá que os conjuntos de dados permaneçam relevantes e valiosos tanto para os interessados da indústria quanto para a comunidade de pesquisa mais ampla.
Fontes & Referências