En djupdykning i IMDB-datasets: Avslöja datan bakom världens största filmdatabas. Upptäck hur dessa datasets omvandlar filmanalytik och forskningen inom branschen.
- Introduktion till IMDB-datasets och deras betydelse
- Översikt över tillgängliga IMDB-dataset-filer
- Datastruktur och schema förklarat
- Åtkomst till och nedladdning av IMDB-data
- Rensning och förbehandling av IMDB-datasets
- Analys av filmbetyg och trender
- Utforskning av skådespelare, team och branschnätverk
- Tillämpningar inom maskininlärning och AI
- Begränsningar, fördomar och överväganden om datakvalitet
- Framtida riktningar och nya användningsområden
- Källor och referenser
Introduktion till IMDB-datasets och deras betydelse
Internet Movie Database (IMDb) är en av världens mest omfattande och auktoritativa källor för information relaterad till filmer, tv-program, videospel och streaminginnehåll. Grundad 1990 har IMDb vuxit till att omfatta miljoner titlar och personligheter, vilket gör den till en kritisk resurs för branschproffs, forskare och entusiaster. IMDb Datasets är kuraterade samlingar av strukturerad data extraherad från huvuddatabasen IMDb, som görs tillgänglig för allmänheten under specifika licensvillkor. Dessa datasets innehåller en mängd information såsom filmtitlar, detaljer om skådespelare och team, utgivningsdatum, genrer, betyg och användarrecensioner.
Betydelsen av IMDb Datasets ligger i deras omfattning, djup och tillförlitlighet. Eftersom datan underhålls och uppdateras av IMDb, en dotterbolag till Amazon, drar de nytta av noggrann datakuratering och en stor användarbas som bidrar till dess noggrannhet. Forskare inom områden som datavetenskap, maskininlärning, samhällsvetenskaper och digital humaniora använder IMDb Datasets för att analysera trender inom medieproduktion och konsumtion, studera genreutveckling och utveckla rekommendationssystem. Till exempel används datasets ofta för att träna algoritmer för att förutsäga filmtjänster, förstå publikens preferenser och kartlägga karriärer för skådespelare och regissörer.
Dessutom främjar den öppna tillgången till IMDb Datasets transparens och reproducerbarhet inom akademisk forskning. Genom att tillhandahålla standardiserade, maskinläsbara data möjliggör IMDb för forskare att validera sina resultat och bygga vidare på tidigare arbete. Datasets är också viktiga i utbildningssammanhang, där studenter lär sig att manipulera verklig data och tillämpa statistiska eller beräkningsmetoder. Utöver akademin utnyttjar branschproffs IMDb Datasets för marknadsanalys, innehållsinanspråk och konkurrensbenchmarking.
Sammanfattningsvis representerar IMDb Datasets en grundläggande resurs för alla som söker att analysera eller förstå den globala underhållningslandskapet. Deras omfattande räckvidd, regelbundna uppdateringar och auktoritativa ursprung gör dem oumbärliga för en mängd analytiska, pedagogiska och kommersiella tillämpningar. Allteftersom underhållningsindustrin fortsätter att utvecklas kommer rollen av strukturerad, tillgänglig data, såsom den som tillhandahålls av IMDb, bara växa i betydelse.
Översikt över tillgängliga IMDB-dataset-filer
Internet Movie Database (IMDb) är en omfattande online-resurs för information relaterad till filmer, tv-program, hemvideo, videospel och streaminginnehåll. För att stödja forskning, dataanalys och applikationsutveckling tillhandahåller IMDb ett urval av nedladdningsbara datasets som täcker ett brett spektrum av underhållningsbranschen data. Dessa datasets görs tillgängliga under IMDb Datasets-initiativet som syftar till att underlätta icke-kommersiell användning och akademisk forskning.
IMDB-datasets distribueras som textfiler i tab-separerade värden (TSV)-format, vilket gör dem tillgängliga för bearbetning med en mängd olika dataanalysverktyg och programmeringsspråk. Varje fil fokuserar på ett specifikt aspekt av databasen, vilket möjliggör för användare att välja enbart den data som är relevant för deras behov. De huvudsakliga dataset-filer som för närvarande är tillgängliga inkluderar:
- title.basics.tsv.gz: Innehåller grundläggande information om titlar, som filmer, tv-serier och avsnitt. Nyckelfält inkluderar titulartype, primära och originaltitlar, utgivningsår, speltid och genre.
- title.akas.tsv.gz: Tillhandahåller alternativa titlar för verk, inklusive regionala och språkspecifika variationer, samt information om landet och språket för varje titelversion.
- title.principals.tsv.gz: Lista över de viktigaste skådespelarna och teamet för varje titel, inklusive skådespelare, regissörer och manusförfattare, tillsammans med deras roller och ordningsföljd.
- title.crew.tsv.gz: Detaljer om regissörer och manusförfattare kopplade till varje titel med unika identifierare för varje person.
- title.episode.tsv.gz: Innehåller avsnittsnivådatan för tv-serier, kopplar avsnitt till sina överordnade serier och tillhandahåller säsong- och avsnittsnummer.
- title.ratings.tsv.gz: Erbjuder användargenererade betyg och antalet röster för varje titel, vilket återspeglar publikens mottagande.
- name.basics.tsv.gz: Innehåller information om personer i branschen, såsom födelse- och dödsår, primära yrken och kända titlar.
Dessa datasets uppdateras regelbundet för att återspegla den senaste informationen i IMDb-databasen. Åtkomst till datasets erbjuds för personlig och icke-kommersiell användning, och användare är skyldiga att följa de användarvillkor som specificeras av IMDb. Datasets används flitigt inom akademisk forskning, maskininlärningsprojekt och datadrivna applikationer som kräver strukturerad information om den globala underhållningsindustrin.
Datastruktur och schema förklarat
IMDB-datasets är en omfattande samling av strukturerade datafiler som tillhandahåller detaljerad information om filmer, tv-program, videospel och relaterade enheter. Dessa datasets görs offentligt tillgängliga av IMDb, ett dotterbolag till Amazon, vilket erkänns som en av världens största och mest auktoritativa källor för metadata för film och tv. Datasets distribueras huvudsakligen i form av tab-separerade värden (TSV) filer, där varje fil representerar ett specifikt aspekt av underhållningsområdet.
Varje IMDb-datasetfil är organiserad som en tabell, med rader som representerar individuella poster och kolumner som motsvarar specifika attribut. Schemat för varje fil är tydligt definierat, vilket säkerställer konsekvens och underlättar automatisk parsering. Till exempel, title.basics.tsv filen innehåller kärninformation om titlar, med kolumner som tconst (en unik identifierare för varje titel), titleType (t.ex. film, tvSerie), primaryTitle, originalTitle, isAdult, startYear, endYear, runtimeMinutes, och genres. Denna struktur gör det möjligt för användare att filtrera och analysera titlar utifrån en mängd olika kriterier.
Andra nyckelfiler inkluderar name.basics.tsv (innehållande information om personer, såsom skådespelare, regissörer och manusförfattare), title.crew.tsv (som listar regissörer och manusförfattare för varje titel), title.principals.tsv (som detaljerar huvudskådespelarna och teamet) och title.ratings.tsv (som tillhandahåller användarbetyg och röstantal). Varje fil använder en unik identifierare—som tconst för titlar och nconst för namn—för att möjliggöra relationella sammanfogningar över datasets, vilket stödjer komplexa frågor och dataintegration.
Schemat är utformat för att vara både läsbart för människor och maskinvänligt, med saknade värden representerade av strängen N. Denna metod säkerställer att datasets enkelt kan importeras i relationsdatabaser, dataanalysverktyg eller programmeringsmiljöer för vidare bearbetning. Den explicita dokumentationen av varje fils schema, inklusive datatyper och fältbeskrivningar, underhålls av IMDb för att stödja transparens och reproducerbarhet i forskning och applikationsutveckling.
Övergripande gör IMDb-datasets strukturerade schema och tydliga dataorganisation dem till en värdefull resurs för datavetare, forskare och utvecklare som är intresserade av att utforska trender, relationer och mönster inom den globala underhållningsindustrin.
Åtkomst till och nedladdning av IMDB-data
Internet Movie Database (IMDb) är en av världens mest omfattande arkiv av information relaterad till filmer, tv-program, videospel och relaterade medier. För forskare, utvecklare och dataentusiaster tillhandahåller IMDb ett urval av nedladdningsbara datasets som möjliggör storskalig analys och applikationsutveckling. Dessa datasets görs tillgängliga genom den officiella IMDb-webbplatsen, som drivs av IMDb.com, Inc., en dotterbolag av Amazon.com, Inc.
Att få tillgång till IMDb-datasets är enkelt. IMDb erbjuder en dedikerad sektion för dataset-nedladdningar, känd som IMDb Datasets-sidan. Här kan användare hitta en samling av textfiler i tab-separerade värden (TSV)-format. Dessa filer täcker ett brett spektrum av data, inklusive grundläggande titelinformation, betyg, detaljer om skådespelare och team, avsnittsguider och mer. Datasets uppdateras regelbundet, vanligtvis varje vecka, för att säkerställa att användare har tillgång till den mest aktuella informationen som finns tillgänglig.
För att ladda ner datasets behöver användare inte registrera sig eller logga in. Filerna är fritt tillgängliga för personlig och icke-kommersiell användning, enligt de licensvillkor som specificeras av IMDb. Varje datasetfil åtföljs av en datadictionary som beskriver fälten och deras betydelser, vilket är avgörande för korrekt tolkning av data och integration. De mest använda filerna inkluderar:
- title.basics.tsv.gz: Innehåller grundläggande information om filmer, tv-program och videospel, såsom titel, utgivningsår och genre.
- title.ratings.tsv.gz: Tillhandahåller IMDb-användarbetyg och röstantal för varje titel.
- name.basics.tsv.gz: Lista över viktiga detaljer om personer i branschen, inklusive skådespelare, regissörer och manusförfattare.
- title.crew.tsv.gz: Detaljer om regissörer och manusförfattare för varje titel.
- title.principals.tsv.gz: Identifierar de viktigaste skådespelarna och teamet för varje titel.
Efter nedladdning kan de komprimerade filerna extraheras och bearbetas med hjälp av standarddataanalysverktyg eller programmeringsspråk som Python eller R. Det öppna formatet och den tydliga dokumentationen gör IMDb-datasets mycket tillgängliga för en mängd olika forsknings- och utvecklingsändamål. Användare bör dock alltid granska licensvillkoren för att säkerställa efterlevnad av IMDB:s användningspolicyer.
För mer information och för att få tillgång till datasets bör användare hänvisa direkt till den officiella IMDb-webbplatsen, som förblir den auktoritativa källan för all IMDb-data och dokumentation.
Rensning och förbehandling av IMDB-datasets
IMDB Datasets, tillhandahållna av IMDb, är en omfattande resurs för film- och tv-data, som används flitigt inom akademisk forskning, datavetenskap och maskininlärningsprojekt. Innan dessa datasets kan användas effektivt för analys eller modellträning är en grundlig rensnings- och förbehandlingsfas avgörande. Denna process säkerställer datakvalitet, konsekvens och lämplighet för efterföljande uppgifter.
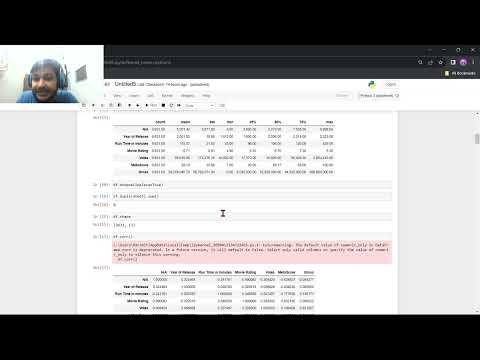
IMDB-datasets distribueras typiskt som tab-separerade värden (TSV)-filer, där varje fil representerar olika aspekter såsom titlar, betyg, team och huvudskådespelare. Det första steget i rensningen innebär att hantera saknade värden, som ofta anges av strängen ”N”. Dessa saknade poster kan dyka upp i fält som födelsedatum, dödsdatum eller sekundära attribut. Beroende på analysmålen kan saknade värden imputeras, tas bort eller flaggas för särskild hantering.
En annan kritisk aspekt är datatypskonvertering. Många fält i IMDB-datasets, såsom år, speltid och betyg, läses in som strängar från början. Att konvertera dessa till lämpliga numeriska eller datetime-format är nödvändigt för korrekt beräkning och analys. Till exempel bör fälten ”startYear” och ”endYear” tolkas som heltal, medan ”averageRating” bör omvandlas till ett flyttal.
Deduplicering är också viktigt, eftersom datasets kan innehålla upprepade poster på grund av uppdateringar eller sammanslagningar från olika datakällor. Att säkerställa att varje film, avsnitt eller person är unikt representerad förhindrar snedvridna resultat i statistiska analyser eller maskininlärningsmodeller.
Normalisering av kategorisk data, såsom genrer eller yrken, är ett annat nyckelsteg i förbehandlingen. IMDB-datasets listar ofta flera genrer eller roller i ett enda fält, separerade av kommatecken. Att dela upp dessa i individuella kategorier eller använda one-hot encoding kan underlätta mer detaljerad analys och modellinmatning.
Slutligen är sammanfogning av flera IMDB-dataset-filer en vanlig förbehandlingsuppgift. Till exempel, att koppla ”title.basics”-filen (som innehåller filmmetadata) med ”title.ratings” (som innehåller användarbetyg) via den unika ”tconst”-identifieraren möjliggör rikare, flerdimensionell analys. Det är viktigt att säkerställa referensintegritet och hantera fall där poster finns i en fil men inte i en annan.
Genom att systematiskt ta itu med saknade värden, datatyper, dubbletter, kategorisk normalisering och datasetintegrering kan forskare och praktiker omvandla rå IMDB-data till ett rent, strukturerat format som är klart för avancerad analys och maskininlärningsapplikationer. Den officiella IMDb-webbplatsen tillhandahåller detaljerad dokumentation och schemabeskrivningar för att vägleda dessa förbehandlingsinsatser.
Analys av filmbetyg och trender
Internet Movie Database (IMDb) är en av världens mest omfattande och auktoritativa källor för information om filmer, tv-program och relaterat innehåll. Dess datasets används flitigt för att analysera filmbetyg och trender och erbjuder en rik resurs för forskare, datavetare och branschproffs. IMDb-datasets görs offentligt tillgängliga för icke-kommersiell användning och uppdateras regelbundet för att återspegla den senaste informationen inom underhållningsindustrin.
IMDb-datasets inkluderar en mängd filer som täcker olika aspekter av film- och tv-data. Nyckeldatasets som är relevanta för analys av filmbetyg och trender inkluderar:
- title.basics.tsv: Innehåller grundläggande information om filmer och tv-program, såsom titel, utgivningsår, speltid och genre.
- title.ratings.tsv: Tillhandahåller genomsnittliga användarbetyg och antalet röster för varje titel, vilket är avgörande för trendanalys och förståelse av publikens preferenser.
- title.akas.tsv: Lista över alternativa titlar och internationella versioner, användbara för analys över marknader.
- name.basics.tsv: Inkluderar data om skådespelare, regissörer och annan nyckelpersonal, vilket möjliggör studier om påverkan av skådespelare och team på betyg.
Genom att utnyttja dessa datasets kan analytiker spåra hur filmbetyg utvecklas över tid, identifiera mönster i publikpreferenser och korrelera betyg med faktorer som genre, utgivningsår eller involvering av specifika skådespelare och regissörer. Till exempel kan tidsserianalys av title.ratings.tsv-filen avslöja trender i publiksentiment, medan korsreferens med title.basics.tsv möjliggör segmentering efter genre eller ursprungsland.
Den öppna tillgången till IMDb-datasets har också möjliggjort utvecklingen av maskininlärningsmodeller för att förutsäga filmtjänster, sentimentanalys av användarrecensioner, och nätverksanalys av samarbeten inom filmindustrin. Dessa datasets används flitigt inom akademisk forskning, branschanalys och av hobbyister som är intresserade av filmdata.
IMDb ägs och drivs av Amazon, vilket säkerställer tillförlitligheten och regelbundna uppdateringar av dess data. Datasets är tillgängliga via den officiella IMDb-webbplatsen, och deras struktur och dokumentation underhålls för att stödja ett brett spektrum av analytiska tillämpningar.
Sammanfattningsvis erbjuder IMDb-datasets en grundläggande resurs för att analysera filmbetyg och trender och stödjer både kvantitativ och kvalitativ forskning om dynamiken inom den globala underhållningsindustrin.
Utforskning av skådespelare, team och branschnätverk
Internet Movie Database (IMDb) är en omfattande online-resurs för information relaterad till filmer, tv-program, hemvideo, videospel och streaminginnehåll. En av dess mest värdefulla tillgångar för forskare och branschproffs är uppsättningen av IMDb Datasets, som tillhandahåller strukturerad data om skådespelare, team och branschnätverk. Dessa datasets görs tillgängliga för icke-kommersiell användning och används flitigt i akademisk forskning, dataanalys och utveckling av underhållningsrelaterade applikationer.
IMDb Datasets inkluderar flera nyckelfiler som underlättar utforskningen av skådespelare och teamrelationer. Filen name.basics.tsv listar individer involverade i underhållningsbranschen, inklusive skådespelare, regissörer, manusförfattare och andra yrkesverksamma, samt deras unika identifierare, födelse- och dödsår och primära yrken. Filen title.principals.tsv kopplar dessa individer till specifika titlar och detaljerar deras roller (som skådespelare, regissör eller producent) och karaktärerna de skildrar eller funktionerna de utför. Denna relationella struktur möjliggör för användare att kartlägga de professionella nätverk som ligger till grund för film- och tv-industrierna.
Genom att utnyttja dessa datasets kan forskare analysera mönster av samarbete, karriärvägar och utvecklingen av kreativa partnerskap. Till exempel kan nätverksanalystekniker tillämpas för att identifiera centrala personer inom branschen, frekventa samarbeten eller uppkomsten av nya talangkluster. Sådana insikter är värdefulla för att förstå dynamiken inom kreativ produktion och de faktorer som bidrar till framgångsrika projekt.
Utöver data om skådespelare och team tillhandahåller IMDb Datasets information om produktionsföretag, genrer, utgivningsdatum och betyg, vilket möjliggör en helhetssyn på branschlandskapet. Filen title.akas.tsv och title.crew.tsv berikar dessutom datasetet genom att erbjuda alternativa titlar och detaljerad information om teamet. Den här omfattande datastrukturen stöder ett brett spektrum av analyser, från mångfaldsstudier till marknadstrendprognoser.
IMDb, som ägs och drivs av Amazon, underhåller och uppdaterar dessa datasets regelbundet, vilket säkerställer att användarna har tillgång till aktuell och historisk information. Datasets är fritt tillgängliga för personlig och icke-kommersiell användning, vilket gör dem till en grundläggande resurs för alla som söker utforska de intrikata nätverken inom underhållningsindustrin. För mer information och åtkomst till datasets kan användare besöka den officiella IMDb-webbplatsen.
Tillämpningar inom maskininlärning och AI
IMDB-datasets, kuraterade och underhållna av Internet Movie Database (IMDb), är bland de mest använda resurserna inom maskininlärning och artificiell intelligens (AI) för forskning och utveckling. Dessa datasets omfattar ett brett spektrum av information, inklusive filmtitlar, detaljer om skådespelare och team, handlingssammanfattningar, användarbetyg och genreklassifikationer. Deras strukturerade och omfattande natur gör dem särskilt värdefulla för en mängd AI-drivna tillämpningar.
En av de mest framträdande användningarna av IMDB-datasets är inom naturlig språkbehandling (NLP), särskilt för sentimentanalys. Den stora IMDB-filmdatataset, till exempel, innehåller tusentals användargenererade filmbetyg märkta som positiva eller negativa, vilket fungerar som en referens för att träna och utvärdera sentimentklassificeringsalgoritmer. Forskare utnyttjar denna dataset för att utveckla och testa modeller som kan automatiskt tolka och klassificera sentimentet som uttrycks i textdata, en kapacitet som sträcker sig till bredare tillämpningar som övervakning av sociala medier och analys av kundfeedback.
Förutom sentimentanalys är IMDB-datasets viktiga för utvecklingen av rekommendationssystem. Genom att analysera användarbetyg, visningshistorik och filmmetadata kan maskininlärningsmodeller förutsäga användarpreferenser och föreslå relevant innehåll. Detta tillvägagångssätt ligger till grund för rekommendationsmotorerna som används av stora streamingplattformar, vilket förbättrar användarengagemanget och tillfredsställelsen. Mångfalden och skalningen av IMDB-data möjliggör utforskning av kollaborativ filtrering, innehållsbaserad filtrering och hybridrekommendationstekniker.
IMDB-datasets underlättar också forskning inom konstruktion av kunskapsgrafer och entitetsupplösning. De rika sammankopplingarna mellan filmer, skådespelare, regissörer och genrer utgör en idealisk grund för att bygga kunskapsgrafer, som är viktiga för semantisk sökning, frågesvar och informationssökning. AI-modeller som tränats på dessa grafer kan besvara komplexa frågor, såsom att identifiera alla filmer med en viss skådespelare inom en specifik genre och tidsram.
Vidare stödjer datasets framsteg inom automatisk innehållstaggning, genreklassifikation och trendanalys. Maskininlärningsalgoritmer kan tränas för att klassificera filmer i genrer baserat på handlingssammanfattningar eller för att upptäcka framväxande trender i filmproduktionen och publikpreferenser över tid. Dessa insikter är värdefulla för studior, marknadsföringsspecialister och forskare som söker förstå och förutsäga förändringar inom underhållningsindustrin.
Sammanfattningsvis är IMDB-datasets, tillhandahållna av IMDb, grundläggande för en bred uppsättning maskininlärnings- och AI-applikationer, och driver innovation inom sentimentanalys, rekommendationssystem, kunskapsrepresentation och mer.
Begränsningar, fördomar och överväganden om datakvalitet
IMDB-datasets, tillhandahållna av IMDb, används flitigt för forskning, analys och applikationsutveckling inom filmstudier, datavetenskap och maskininlärning. Men användare måste vara medvetna om flera begränsningar, fördomar och datakvalitetsöverväganden som är inneboende i dessa datasets.
En huvudbegränsning är räckvidden och fullständigheten av datan. Även om IMDb strävar efter att upprätthålla en omfattande databas av filmer, tv-program och relaterade personer, är datasetet till största delen crowd-sourcat. Detta innebär att inkluderingen och noggrannheten av information beror på användarbidrag och redaktionell tillsyn. Som ett resultat kan mindre kända titlar, produktioner på andra språk och oberoende filmer vara underrepresenterade eller sakna detaljerad metadata. Dessutom kan vissa datafält—som handlingssammanfattningar, genre-taggar eller rolliste—vara ofullständiga eller inkonsekvent formaterade över poster.
Bias är en annan viktig övervägande. IMDb-användarbasen, som bidrar med betyg och recensioner, är inte nödvändigtvis representativ för den globala befolkningen. Demografiska snedvridningar—som ålder, kön eller geografisk plats—kan påverka aggregerade betyg och popularitetsmetrik. Till exempel kan filmer som tilltalar yngre eller engelsktalande publik få oproportionerligt hög synlighet och betyg, medan verk från andra regioner eller genrer kan förbises. Detta introducerar en urvals-bias som kan påverka forskningsresultat eller algoritmiska rekommendationer som bygger på IMDb-data.
Datakvaliteten påverkas också av den dynamiska och utvecklande naturen hos databasen. Poster uppdateras, korrigeras eller utökas ofta, vilket kan leda till inkonsekvenser över tid. Till exempel kan en films utgivningsdatum, rollista eller betyg ändras när ny information blir tillgänglig. Forskare som använder statiska ögonblicksbilder av datasetet bör vara försiktiga med tidsmässiga inkonsekvenser och se till att deras analyser tar hänsyn till möjliga uppdateringar eller korrigeringar.
Dessutom inför IMDB:s datalicenser begränsningar på användning, särskilt för kommersiella applikationer. Datasets tillhandahålls för personlig och icke-kommersiell användning, och användare måste följa de villkor som anges av IMDb. Detta kan begränsa omfattningen av projekt eller kräva ytterligare tillstånd för bredare användning.
Sammanfattningsvis, medan IMDb-datasets är en värdefull resurs, måste användare kritiskt bedöma deras fullständighet, potentiella snedvridningar och datakvalitetsproblem. Noggrant övervägande av dessa faktorer är avgörande för ansvarsfull och exakt analys, särskilt inom akademiska eller kommersiella sammanhang.
Framtida riktningar och nya användningsområden
Framtiden för IMDB-datasets formas av utvecklande teknologier, expanderande användarbehov och den växande betydelsen av datadrivna insikter inom underhållningsindustrin. Som en av de mest omfattande och mest använda arkiven av film- och tv-metadata är IMDB-datasets—underhållna och distribuerade av IMDb, ett dotterbolag till Amazon—redo för betydande framsteg och nya tillämpningar.
En viktig riktning är integrationen av IMDB-datasets med artificiell intelligens (AI) och maskininlärningssystem. Forskare och utvecklare utnyttjar i allt högre grad dessa datasets för att träna rekommendationsmotorer, sentimentanalysmodeller och prediktiva analysverktyg. Till exempel, genom att kombinera IMDB:s rika metadata med användarinteraktionsdata kan streamingplattformar förfina personliga innehållsförslag, optimera katalogkurering och förutsäga publiktrender. Allteftersom AI-modeller blir mer sofistikerade kommer efterfrågan på granulär, aktuell och väldefinierad underhållningsdata bara öka.
Ett annat framväxande användningsområde ligger inom naturlig språkbehandling (NLP). IMDB:s omfattande samling av användarrecensioner, handlingssammanfattningar och skådespelarinformation utgör en värdefull korpus för att utveckla och utvärdera NLP-algoritmer. Dessa tillämpningar sträcker sig från automatiserad innehållsmoderering och sammanfattning av recensioner till extraktion av tematiska element och sentimenttrender över genrer och tidsperioder.
IMDB-datasets får också nytt relevans inom akademisk forskning och samhällsvetenskaper. Forskare använder data för att studera representation, mångfald och kulturella trender inom media. Genom att analysera skådespelardemografi, genreutveckling och internationella samarbeten kan forskare få insikter om bredare samhällsförändringar och de globala dynamikerna inom underhållningsindustrin.
Ser vi framåt, är interoperabiliteten av IMDB-datasets med andra öppna datainitiativ troligtvis kommer att expandera. Att koppla IMDB-data med källor som Wikidata eller Library of Congress kan möjliggöra rikare analyser över domäner och stödja projekt inom digital humaniora, konstruktion av kunskapsgrafer och utveckling av semantisk web.
Slutligen, när underhållningslandskapet diversifieras med ökningen av nya medieformat—som webbserier, podcaster och interaktivt innehåll—finns det ett växande behov av att IMDB-datasets ska utvecklas och fånga dessa framväxande former. Denna expansion kommer att säkerställa att datasets förblir relevanta och värdefulla för både branschaktörer och den bredare forskarsamhället.
Källor och referenser